Meituan has released LongCat-2.0, a large-scale Mixture-of-Experts (MoE) language model. It carries 1.6 trillion total parameters and activates about 48 billion per token. The model targets agentic coding: code understanding, generation, and execution inside agent workflows.
Two facts stand out. First, LongCat-2.0 supports a native 1-million-token context window. Second, both training and serving ran entirely on domestic AI ASIC superpods.
What is LongCat-2.0?
LongCat-2.0 is Meituan’s next-generation trillion-parameter open model. It follows LongCat-Flash, a 560B model released in 2025. The architecture was designed around one goal: reliable, efficient agentic coding.
Pretraining spanned more than 35 trillion tokens over millions of accelerator-hours. Meituan reports no rollbacks or irrecoverable loss spikes during the run. That stability claim matters on non-Nvidia hardware, where tooling is less mature.
Architecture: How a 1.6T Model Stays Cheap to Run
The design combines four ideas that reduce the cost of scale. Each one is worth understanding on its own.
- Zero-computation experts: Not every token needs heavy compute. Simple tokens like punctuation route to a zero-computation expert and return unchanged. Complex tokens engage more expert capacity. A PID controller adjusts expert bias to hold the average in range. This produces the 33B–56B dynamic activation window instead of a fixed cost. The MoE backbone uses a shortcut-connected design (ScMoE) for higher throughput.
- LongCat Sparse Attention (LSA): Standard attention scales quadratically with context length. LSA selects only the most relevant tokens, dropping the scaling closer to linear. Meituan describes it as an evolution of DeepSeek Sparse Attention (DSA). It layers three orthogonal indexing methods. Streaming-aware Indexing turns fragmented memory reads into contiguous blocks. Cross-Layer Indexing reuses attention saliency across adjacent layers. Hierarchical Indexing applies coarse-to-fine two-stage filtering. Together they sustain the 1M-token window without a memory wall.
- N-gram Embedding: The design adds a 135-billion-parameter N-gram embedding module. It sits orthogonal to the MoE experts in sparse dimensions. Meituan says it captures dense local token relationships. It also reduces memory I/O during large-batch decoding.
- Post-training (MOPD): A dedicated pipeline (MOPD) fuses three teacher expert groups. These cover Agent, Reasoning, and Interaction capabilities into one unified model.
For serving, Meituan uses a 6D parallelism scheme and a prefill-decode disaggregated architecture. It also employs ‘super kernels’ and L2-cache weight prefetching to hide I/O latency.
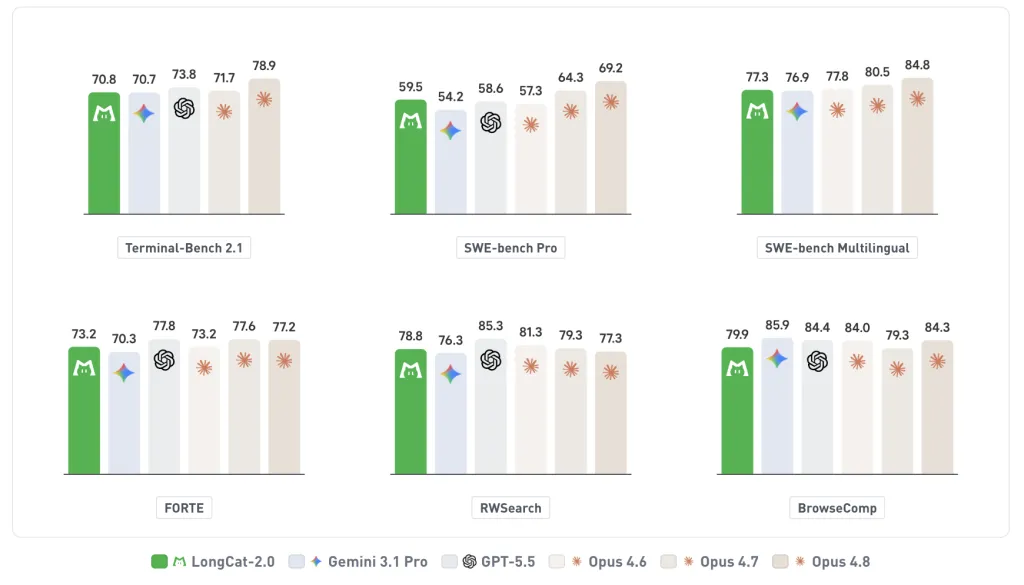
Benchmarks
Meituan positions LongCat-2.0 as an agentic coding model. Every figure below comes from Meituan’s own testing.
| Benchmark | LongCat-2.0 | What it measures |
|---|---|---|
| SWE-bench Pro | 59.5 | Real-world software engineering tasks |
| Terminal-Bench 2.1 | 70.8 | Execution and error recovery in shells |
| SWE-bench Multilingual | 77.3 | Cross-language repository tasks |
On SWE-bench Pro, Meituan reports LongCat-2.0 edging GPT-5.5 (58.6). Meituan also claims overall performance comparable to Google’s Gemini 3.1 Pro. The reported edge is concentrated in software engineering. On broader general-agent benchmarks such as FORTE and BrowseComp, coverage indicates it trails leading frontier systems. Independent leaderboard confirmation is not yet available.
LongCat-2.0 vs LongCat-Flash
The jump from the previous generation is large on paper. This table uses each model’s published specifications.
| Attribute | LongCat-2.0 | LongCat-Flash |
|---|---|---|
| Total parameters | 1.6T | 560B |
| Active per token | ~48B (33B–56B) | ~27B (18.6B–31.3B) |
| Context window | 1M tokens (native) | 128K tokens |
| Long-context attention | LongCat Sparse Attention | Multi-head Latent Attention |
| Reported hardware | Domestic AI ASIC superpods (training + serving) | H800 GPUs (inference reported) |
| Max output | 128K tokens | Not specified |
| License | MIT | MIT |
| Released | June 30, 2026 | September 2025 |
| Weights | Coming soon | Open |
Use Cases With Examples
LongCat-2.0 is tuned for agent-style software work, not casual chat. A few concrete patterns fit its strengths.
- Whole-repository reasoning: Feed an entire mid-sized codebase into the 1M-token window. Ask the model to trace a bug across many files at once. This avoids the summarization hacks that shorter windows force.
- Multi-step terminal tasks: Run the model inside an agent loop with shell access. It can execute commands, read errors, and retry until a task passes. The Terminal-Bench 2.1 focus targets exactly this workflow.
- Repository-level edits: Ask for a refactor that spans several modules and tests. The model reasons over the full context before proposing coordinated changes.
- Cross-language migration: Use the SWE-bench Multilingual strength for polyglot repositories. The model can port logic between languages while preserving behavior.
These patterns run inside standard agent harnesses. Dev teams can therefore adopt the model without building new tooling.
How to Access It
LongCat-2.0 is reachable through the LongCat API Platform. It exposes both OpenAI-compatible and Anthropic-compatible endpoints. The model is also on OpenRouter and in harnesses like Claude Code, OpenClaw, OpenCode, and Codex. Local self-hosting is not yet possible, since weights remain pending.
The OpenAI-compatible endpoint uses the model ID LongCat-2.0. Maximum output length is 131072 tokens (128K). The snippet below calls the documented chat-completions endpoint.
# pip install openai
from openai import OpenAI
client = OpenAI(
api_key="YOUR_LONGCAT_API_KEY",
base_url="https://api.longcat.chat/openai/v1",
)
resp = client.chat.completions.create(
model="LongCat-2.0",
messages=[
{"role": "system", "content": "You are a coding agent."},
{"role": "user", "content": "Refactor utils.py to remove duplicate I/O logic."},
],
max_tokens=4096, # LongCat-2.0 supports up to 131072 (128K)
)
print(resp.choices[0].message.content)Pricing is reported at $0.75 per million input tokens and $2.95 per million output. A launch promotion lists $0.30 and $1.20, with cached context reads free. These figures come from third-party coverage and may change.
Interactive Explainer
Key Takeaways
- Released under MIT
- LongCat-2.0 is a 1.6T-parameter MoE model activating ~48B parameters per token (dynamic range 33B–56B).
- Native 1M-token context comes from LongCat Sparse Attention, cutting long-context cost from quadratic to linear.
- Training and inference ran on a 50,000-card domestic AI ASIC cluster, with no Nvidia hardware.
- Vendor-reported scores: 59.5 SWE-bench Pro, 70.8 Terminal-Bench 2.1, 77.3 SWE-bench Multilingual.
Check out the Model Weights, GitHub Repo and Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us