
Qwen group has simply launched Qwen3-Coder-Subsequent, an open-weight language mannequin designed for coding brokers and native growth. It sits on prime of the Qwen3-Subsequent-80B-A3B spine. The mannequin makes use of a sparse Combination-of-Consultants (MoE) structure with hybrid consideration. It has 80B complete parameters, however solely 3B parameters are activated per token. The objective is to match the efficiency of a lot bigger energetic fashions whereas holding inference value low for lengthy coding periods and agent workflows.
The mannequin is positioned for agentic coding, browser-based instruments, and IDE copilots slightly than easy code completion. Qwen3-Coder-Subsequent is skilled with a big corpus of executable duties and reinforcement studying in order that it may well plan, name instruments, run code, and get well from runtime failures throughout lengthy horizons.
Structure: Hybrid Consideration Plus Sparse MoE
The analysis group describes it as a hybrid structure that mixes Gated DeltaNet, Gated Consideration, and MoE.
Key configuration factors are:
- Sort: causal language mannequin, pretraining plus post-training.
- Parameters: 80B in complete, 79B non-embedding.
- Lively parameters: 3B per token.
- Layers: 48.
- Hidden dimension: 2048.
- Format: 12 repetitions of
3 × (Gated DeltaNet → MoE)adopted by1 × (Gated Consideration → MoE).
The Gated Consideration block makes use of 16 question heads and a couple of key-value heads with head dimension 256 and rotary place embeddings of dimension 64. The Gated DeltaNet block makes use of 32 linear-attention heads for values and 16 for queries and keys with head dimension 128.
The MoE layer has 512 specialists, with 10 specialists and 1 shared knowledgeable energetic per token. Every knowledgeable makes use of an intermediate dimension of 512. This design provides sturdy capability for specialization, whereas the energetic compute stays close to a 3B dense mannequin footprint.
Agentic Coaching: Executable Duties And RL
Qwen group describes Qwen3-Coder-Subsequent as ‘agentically skilled at scale’ on prime of Qwen3-Subsequent-80B-A3B-Base. The coaching pipeline makes use of large-scale executable process synthesis, interplay with environments, and reinforcement studying.
It spotlight about 800K verifiable duties with executable environments used throughout coaching. These duties present concrete alerts for long-horizon reasoning, software sequencing, take a look at execution, and restoration from failing runs. That is aligned with SWE-Bench-style workflows slightly than pure static code modeling.
Benchmarks: SWE-Bench, Terminal-Bench, And Aider
On SWE-Bench Verified utilizing the SWE-Agent scaffold, Qwen3-Coder-Subsequent scores 70.6. DeepSeek-V3.2 at 671B parameters scores 70.2, and GLM-4.7 at 358B parameters scores 74.2. On SWE-Bench Multilingual, Qwen3-Coder-Subsequent reaches 62.8, very near DeepSeek-V3.2 at 62.3 and GLM-4.7 at 63.7. On the more difficult SWE-Bench Professional, Qwen3-Coder-Subsequent scores 44.3, above DeepSeek-V3.2 at 40.9 and GLM-4.7 at 40.6.
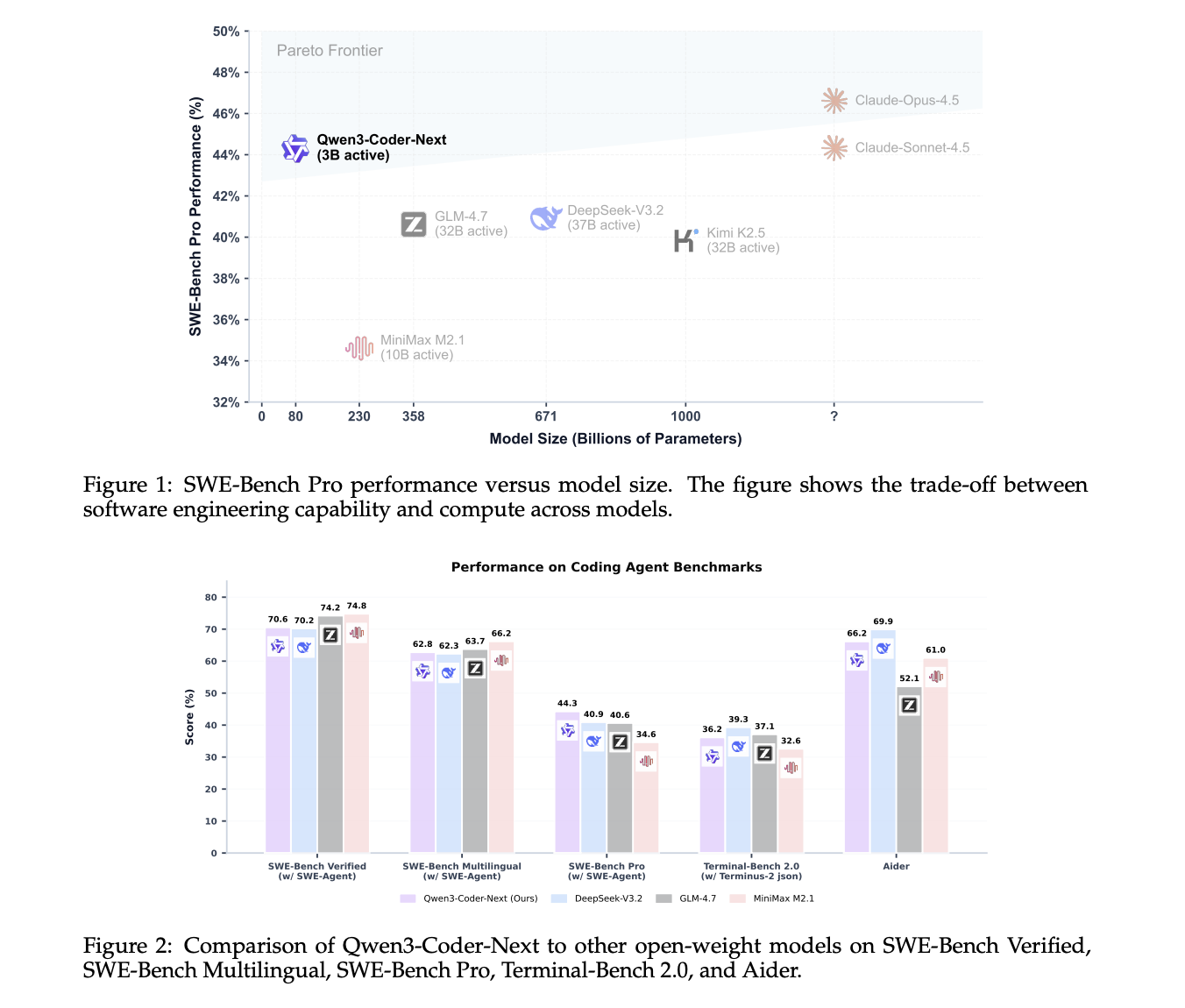
On Terminal-Bench 2.0 with the Terminus-2 JSON scaffold, Qwen3-Coder-Subsequent scores 36.2, once more aggressive with bigger fashions. On the Aider benchmark, it reaches 66.2, which is near the very best fashions in its class.
These outcomes help the declare from the Qwen group that Qwen3-Coder-Subsequent achieves efficiency similar to fashions with 10–20× extra energetic parameters, particularly in coding and agentic settings.
Instrument Use And Agent Integrations
Qwen3-Coder-Subsequent is tuned for software calling and integration with coding brokers. The mannequin is designed to plug into IDE and CLI environments akin to Qwen-Code, Claude-Code, Cline, and different agent frontends. The 256K context lets these methods hold giant codebases, logs, and conversations in a single session.
Qwen3-Coder-Subsequent helps solely non-thinking mode. Each the official mannequin card and Unsloth documentation stress that it doesn’t generate
Deployment: SGLang, vLLM, And Native GGUF
For server deployment, Qwen group recommends SGLang and vLLM. In SGLang, customers run sglang>=0.5.8 with --tool-call-parser qwen3_coder and a default context size of 256K tokens. In vLLM, customers run vllm>=0.15.0 with --enable-auto-tool-choice and the identical software parser. Each setups expose an OpenAI-compatible /v1 endpoint.
For native deployment, Unsloth provides GGUF quantizations of Qwen3-Coder-Subsequent and a full llama.cpp and llama-server workflow. A 4-bit quantized variant wants about 46 GB of RAM or unified reminiscence, whereas 8-bit wants about 85 GB. The Unsloth information recommends context sizes as much as 262,144 tokens, with 32,768 tokens as a sensible default for smaller machines.
The Unsloth guide additionally exhibits the right way to hook Qwen3-Coder-Subsequent into native brokers that emulate OpenAI Codex and Claude Code. These examples depend on llama-server with an OpenAI-compatible interface and reuse agent immediate templates whereas swapping the mannequin title to Qwen3-Coder-Subsequent.
Key Takeaways
- MoE structure with low energetic compute: Qwen3-Coder-Subsequent has 80B complete parameters in a sparse MoE design, however solely 3B parameters are energetic per token, which reduces inference value whereas holding excessive capability for specialised specialists.
- Hybrid consideration stack for long-horizon coding: The mannequin makes use of a hybrid structure of Gated DeltaNet, Gated Consideration, and MoE blocks over 48 layers with a 2048 hidden dimension, optimized for long-horizon reasoning in code modifying and agent workflows.
- Agentic coaching with executable duties and RL: Qwen3-Coder-Subsequent is skilled on large-scale executable duties and reinforcement studying on prime of Qwen3-Subsequent-80B-A3B-Base, so it may well plan, name instruments, run assessments, and get well from failures as an alternative of solely finishing quick code snippets.
- Aggressive efficiency on SWE-Bench and Terminal-Bench: Benchmarks present that Qwen3-Coder-Subsequent reaches sturdy scores on SWE-Bench Verified, SWE-Bench Professional, SWE-Bench Multilingual, Terminal-Bench 2.0, and Aider, typically matching or surpassing a lot bigger MoE fashions with 10–20× extra energetic parameters.
- Sensible deployment for brokers and native use: The mannequin helps 256K context, non-thinking mode, OpenAI-compatible APIs by way of SGLang and vLLM, and GGUF quantizations for llama.cpp, making it appropriate for IDE brokers, CLI instruments, and native personal coding copilots beneath Apache-2.0.
Try the Paper, Repo, Model Weights and Technical details. Additionally, be at liberty to observe us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
