MoonshotAI has open-sourced checkpoint-engine, a light-weight middleware geared toward fixing one of many key bottlenecks in giant language mannequin (LLM) deployment: quickly updating mannequin weights throughout 1000’s of GPUs with out disrupting inference.
The library is especially designed for reinforcement studying (RL) and reinforcement studying with human suggestions (RLHF), the place fashions are up to date steadily and downtime straight impacts system throughput.
How Quick can LLMs be up to date?
Checkpoint-engine delivers a major breakthrough by updating a 1-trillion parameter mannequin throughout 1000’s of GPUs in roughly 20 seconds.
Conventional distributed inference pipelines can take a number of minutes to reload fashions of this dimension. By decreasing the replace time by an order of magnitude, checkpoint-engine straight addresses one of many largest inefficiencies in large-scale serving.
The system achieves this by:
- Broadcast updates for static clusters.
- Peer-to-peer (P2P) updates for dynamic clusters.
- Overlapped communication and reminiscence copy for lowered latency.
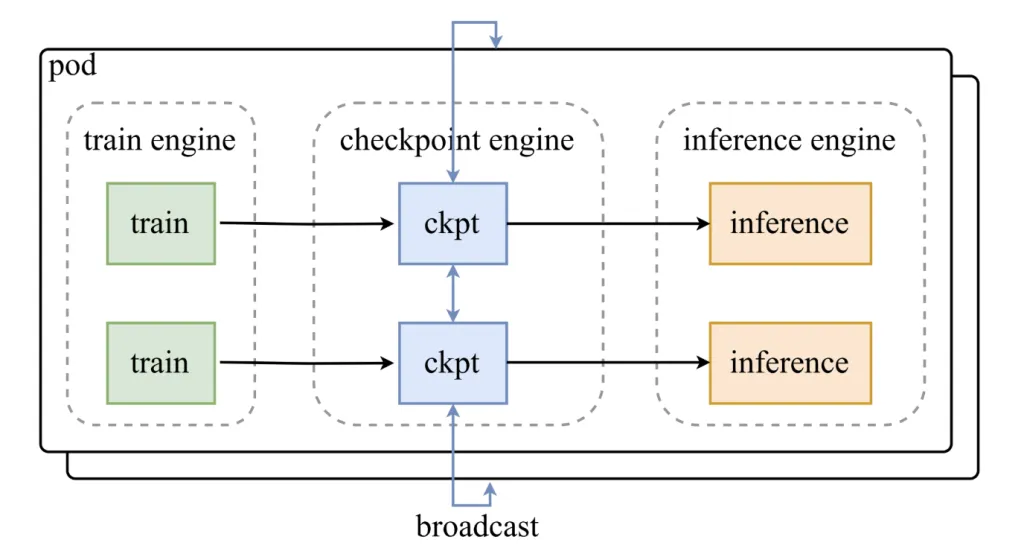
What does the Structure seem like?
Checkpoint-engine sits between coaching engines and inference clusters. Its design contains:
- A Parameter Server that coordinates updates.
- Employee Extensions that combine with inference frameworks reminiscent of vLLM.
The load replace pipeline runs in three phases:
- Host-to-Machine (H2D): Parameters are copied into GPU reminiscence.
- Broadcast: Weights are distributed throughout employees utilizing CUDA IPC buffers.
- Reload: Every inference shard reloads solely the subset of weights it wants.
This staged pipeline is optimized for overlap, guaranteeing GPUs stay energetic all through the replace course of.
How does it carry out in apply?
Benchmarking outcomes verify checkpoint-engine’s scalability:
- GLM-4.5-Air (BF16, 8×H800): 3.94s (broadcast), 8.83s (P2P).
- Qwen3-235B-Instruct (BF16, 8×H800): 6.75s (broadcast), 16.47s (P2P).
- DeepSeek-V3.1 (FP8, 16×H20): 12.22s (broadcast), 25.77s (P2P).
- Kimi-K2-Instruct (FP8, 256×H20): ~21.5s (broadcast), 34.49s (P2P).
Even at trillion-parameter scale with 256 GPUs, broadcast updates full in about 20 seconds, validating its design aim.
What are some trade-offs?
Checkpoint-engine introduces notable benefits, but in addition comes with limitations:
- Reminiscence Overhead: Overlapped pipelines require further GPU reminiscence; inadequate reminiscence triggers slower fallback paths.
- P2P Latency: Peer-to-peer updates assist elastic clusters however at a efficiency value.
- Compatibility: Formally examined with vLLM solely; broader engine assist requires engineering work.
- Quantization: FP8 assist exists however stays experimental.
The place does it slot in deployment eventualities?
Checkpoint-engine is Most worthy for:
- Reinforcement studying pipelines the place frequent weight updates are required.
- Giant inference clusters serving 100B–1T+ parameter fashions.
- Elastic environments with dynamic scaling, the place P2P flexibility offsets latency trade-offs.
Abstract
Checkpoint-engine represents a targeted answer to one of many hardest issues in large-scale LLM deployment: speedy weight synchronization with out halting inference. With demonstrated updates at trillion-parameter scale in round 20 seconds, versatile assist for each broadcast and P2P modes, and an optimized communication pipeline, it supplies a sensible path ahead for reinforcement studying pipelines and high-performance inference clusters. Whereas nonetheless restricted to vLLM and requiring refinements in quantization and dynamic scaling, it establishes an vital basis for environment friendly, steady mannequin updates in manufacturing AI methods.
Take a look at the PROJECT PAGE here. Be happy to take a look at our GitHub Page for Tutorials, Codes and Notebooks. Additionally, be happy to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our Newsletter.
Max is an AI analyst at MarkTechPost, based mostly in Silicon Valley, who actively shapes the way forward for expertise. He teaches robotics at Brainvyne, combats spam with ComplyEmail, and leverages AI each day to translate advanced tech developments into clear, comprehensible insights