: The Audiovisual Encoder Powering SAM Audio And Giant Scale Multimodal Retrieval")
Meta researchers have launched Notion Encoder Audiovisual, PEAV, as a brand new household of encoders for joint audio and video understanding. The mannequin learns aligned audio, video, and textual content representations in a single embedding area utilizing massive scale contrastive coaching on about 100M audio video pairs with textual content captions.
From Notion Encoder to PEAV
Notion Encoder, PE, is the core imaginative and prescient stack in Meta’s Notion Fashions undertaking. It’s a household of encoders for photographs, video, and audio that reaches cutting-edge on many imaginative and prescient and audio benchmarks utilizing a unified contrastive pretraining recipe. PE core surpasses SigLIP2 on picture duties and InternVideo2 on video duties. PE lang powers Notion Language Mannequin for multimodal reasoning. PE spatial is tuned for dense prediction duties similar to detection and depth estimation.
PEAV builds on this spine and extends it to full audio video textual content alignment. Within the Notion Fashions repository, PE audio visible is listed because the department that embeds audio, video, audio video, and textual content right into a single joint embedding area for cross modal understanding.
Structure, Separate Towers and Fusion
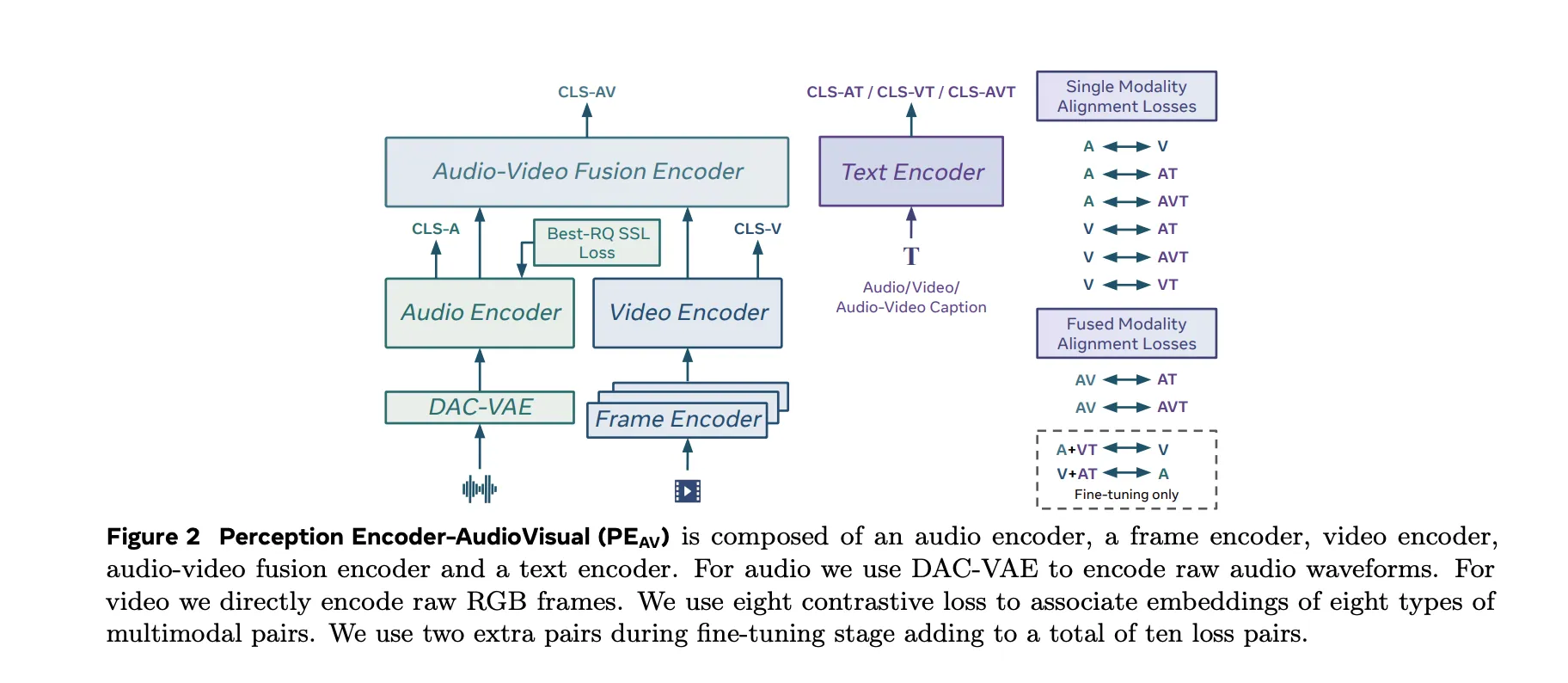
The PEAV structure consists of a body encoder, a video encoder, an audio encoder, an audio video fusion encoder, and a textual content encoder.
- The video path makes use of the prevailing PE body encoder on RGB frames, then applies a temporal video encoder on prime of body degree options.
- The audio path makes use of DAC VAE as a codec to transform uncooked waveforms into discrete audio tokens at mounted body price, about one embedding each 40 milliseconds.
These towers feed an audio video fusion encoder that learns a shared illustration for each streams. The textual content encoder initiatives textual content queries into a number of specialised areas. In apply this offers you a single spine that may be queried in some ways. You’ll be able to retrieve video from textual content, audio from textual content, audio from video, or retrieve textual content descriptions conditioned on any mixture of modalities with out retraining job particular heads.
Information Engine, Artificial Audiovisual Captions At Scale
The analysis group proposed a two stage audiovisual information engine that generates top quality artificial captions for unlabeled clips. The group describes a pipeline that first makes use of a number of weak audio caption fashions, their confidence scores, and separate video captioners as enter to a big language mannequin. This LLM produces three caption sorts per clip, one for audio content material, one for visible content material, and one for joint audio visible content material. An preliminary PE AV mannequin is educated on this artificial supervision.
Within the second stage, this preliminary PEAV is paired with a Notion Language Mannequin decoder. Collectively they refine the captions to raised exploit audiovisual correspondences. The 2 stage engine yields dependable captions for about 100M audio video pairs and makes use of about 92M distinctive clips for stage 1 pretraining and 32M extra distinctive clips for stage 2 positive tuning.
In comparison with prior work that usually focuses on speech or slim sound domains, this corpus is designed to be balanced throughout speech, common sounds, music, and various video domains, which is vital for common audio visible retrieval and understanding.
Contrastive Goal Throughout Ten Modality Pairs
PEAV makes use of a sigmoid based mostly contrastive loss throughout audio, video, textual content, and fused representations. The analysis group explains that the mannequin makes use of eight contrastive loss pairs throughout pretraining. These cowl combos similar to audio textual content, video textual content, audio video textual content, and fusion associated pairs. Throughout positive tuning, two further pairs are added, which brings the whole to 10 loss pairs among the many completely different modality and caption sorts.
This goal is comparable in type to contrastive aims utilized in current imaginative and prescient language encoders however generalized to audio video textual content tri modal coaching. By aligning all these views in a single area, the identical encoder can assist classification, retrieval, and correspondence duties with easy dot product similarities.
Efficiency Throughout Audio, Speech, Music And Video
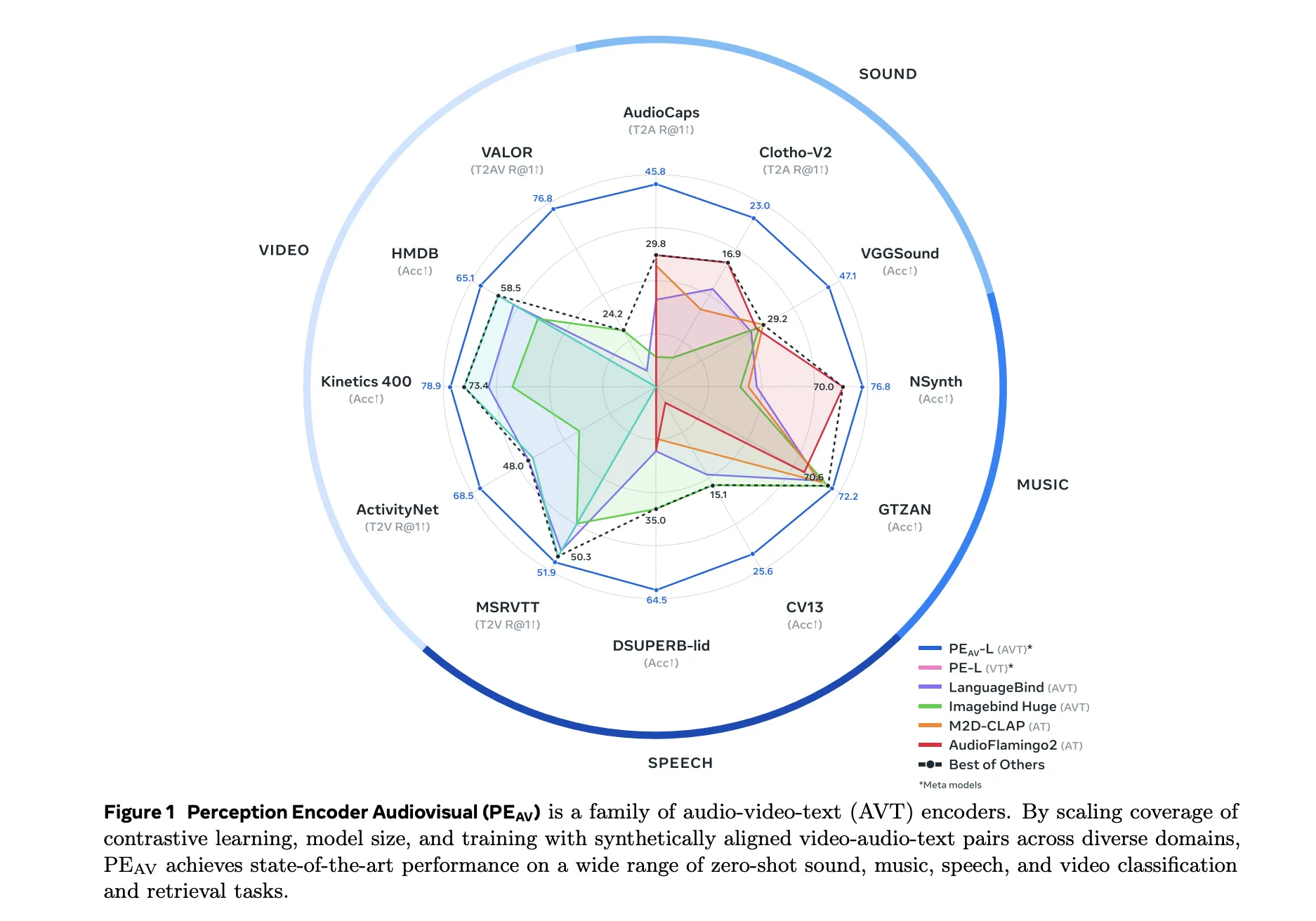
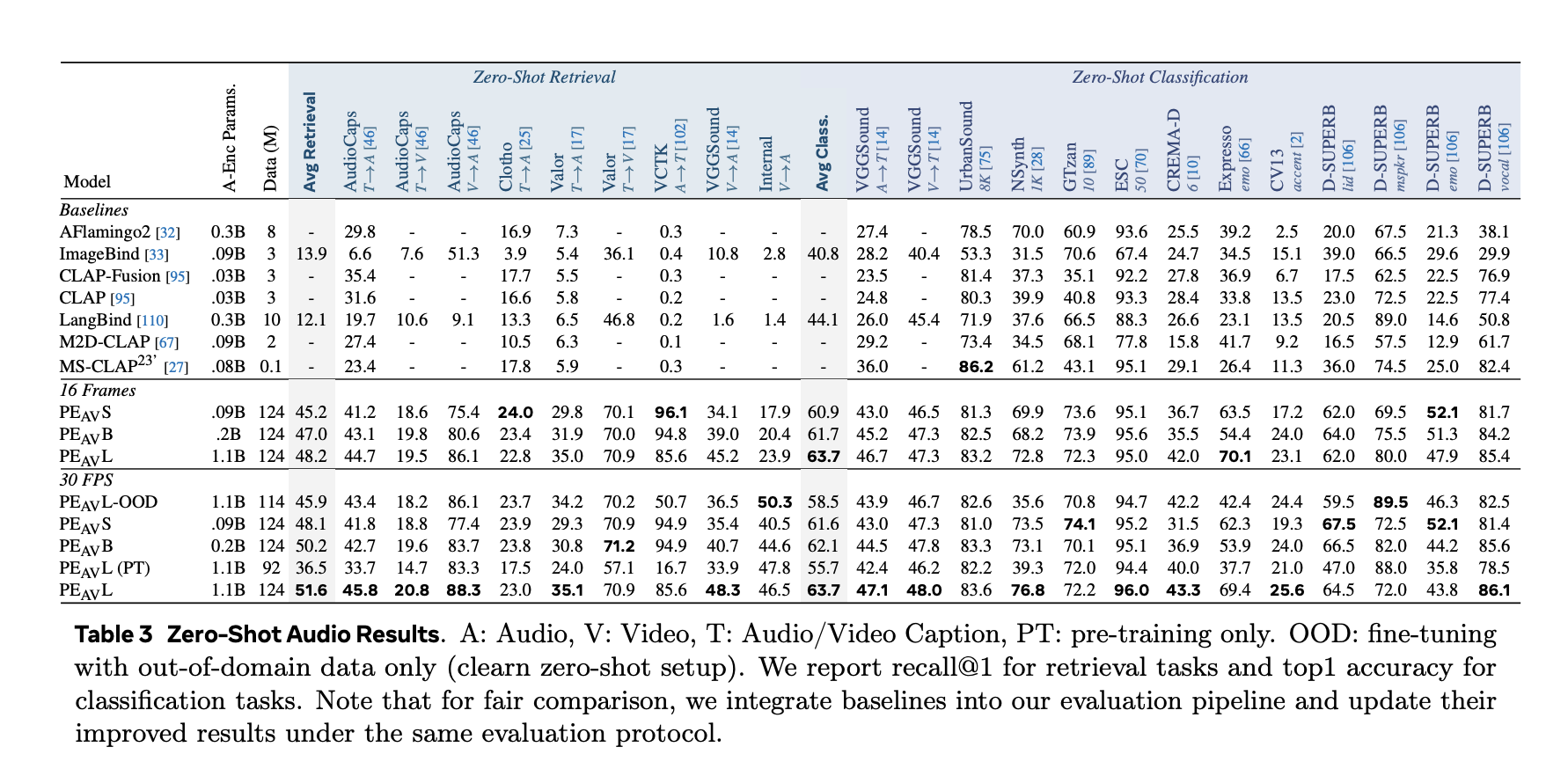
On benchmarks, PEAV targets zero shot retrieval and classification for a number of domains. PE AV achieves cutting-edge efficiency on a number of audio and video benchmarks in comparison with current audio textual content and audio video textual content fashions from works similar to CLAP, Audio Flamingo, ImageBind, and LanguageBind.
Concrete good points embrace:
- On AudioCaps, textual content to audio retrieval improves from 35.4 R at 1 to 45.8 R at 1.
- On VGGSound, clip degree classification accuracy improves from 36.0 to 47.1.
- For speech retrieval on VCTK fashion duties, PE AV reaches 85.6 accuracy whereas earlier fashions are close to 0.
- On ActivityNet, textual content to video retrieval improves from 60.4 R at 1 to 66.5 R at 1.
- On Kinetics 400, zero shot video classification improves from 76.9 to 78.9, beating fashions 2 to 4 occasions bigger.
PEA-Body, Body Stage Audio Textual content Alignment
Alongside PEAV, Meta releases Notion Encoder Audio Body, PEA-Body, for sound occasion localization. PE A Body is an audio textual content embedding mannequin that outputs one audio embedding per 40 milliseconds body and a single textual content embedding per question. The mannequin can return temporal spans that mark the place within the audio every described occasion happens.
PEA-Body makes use of body degree contrastive studying to align audio frames with textual content. This permits exact localization of occasions similar to particular audio system, devices, or transient sounds in lengthy audio sequences.
Function In The Notion Fashions And SAM Audio Ecosystem
PEAV and PEA-Body sit contained in the broader Notion Fashions stack, which mixes PE encoders with Notion Language Mannequin for multimodal era and reasoning.
PEAV can be the core notion engine behind Meta’s new SAM Audio mannequin and its Decide evaluator. SAM Audio makes use of PEAV embeddings to attach visible prompts and textual content prompts to sound sources in complicated mixtures and to attain the standard of separated audio tracks.
Key Takeaways
- PEAV is a unified encoder for audio, video, and textual content, educated with contrastive studying on over 100M movies, and embeds audio, video, audio video, and textual content right into a single joint area for cross modal retrieval and understanding.
- The structure makes use of separate video and audio towers, with PE based mostly visible encoding and DAC VAE audio tokenization, adopted by an audio visible fusion encoder and specialised textual content heads aligned to completely different modality pairs.
- A 2 stage information engine generates artificial audio, visible, and audio visible captions utilizing weaker captioners plus an LLM in stage 1 and PEAV plus Notion Language Mannequin in stage 2, enabling massive scale multimodal supervision with out handbook labels.
- PEAV establishes new cutting-edge on a variety of audio and video benchmarks by way of a sigmoid contrastive goal over a number of modality pairs, with six public checkpoints from small 16 body to massive all body variants, the place common retrieval improves from about 45 to 51.6.
- PEAV, along with the body degree PEA-Body variant, varieties the notion spine for Meta’s SAM Audio system, offering the embeddings used for immediate based mostly audio separation and positive grained sound occasion localization throughout speech, music, and common sounds.
Try the Paper, Repo and Model Weights. Additionally, be happy to comply with us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.