
dots.ocr is an open-source vision-language transformer mannequin developed for multilingual doc format parsing and optical character recognition (OCR). It performs each format detection and content material recognition inside a single structure, supporting over 100 languages and all kinds of structured and unstructured doc varieties.
Structure
- Unified Mannequin: dots.ocr combines format detection and content material recognition right into a single transformer-based neural community. This eliminates the complexity of separate detection and OCR pipelines, permitting customers to modify duties by adjusting enter prompts.
- Parameters: The mannequin incorporates 1.7 billion parameters, balancing computational effectivity with efficiency for many sensible situations.
- Enter Flexibility: Inputs could be picture information or PDF paperwork. The mannequin options preprocessing choices (similar to fitz_preprocess) for optimizing high quality on low-resolution or dense multi-page information.
Capabilities
- Multilingual: dots.ocr is educated on datasets spanning greater than 100 languages, together with main world languages and fewer frequent scripts, reflecting broad multilingual help.
- Content material Extraction: The mannequin extracts plain textual content, tabular knowledge, mathematical formulation (in LaTeX), and preserves studying order inside paperwork. Output codecs embrace structured JSON, Markdown, and HTML, relying on the format and content material sort.
- Preserves Construction: dots.ocr maintains doc construction, together with desk boundaries, system areas, and picture placements, making certain extracted knowledge stays devoted to the unique doc.
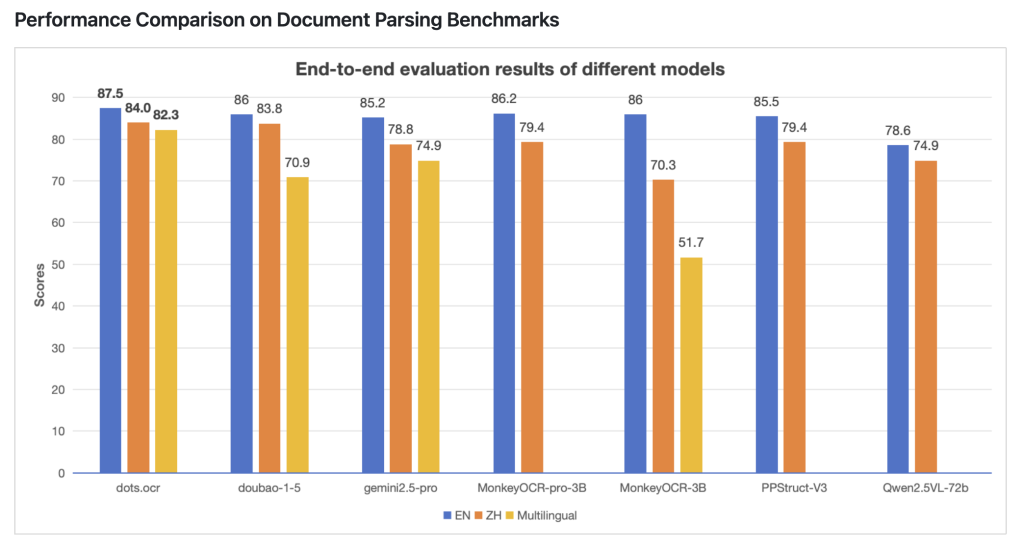
Benchmark Efficiency
dots.ocr has been evaluated towards fashionable doc AI programs, with outcomes summarized under:
| Benchmark | dots.ocr | Gemini2.5-Professional |
|---|---|---|
| Desk TEDS accuracy | 88.6% | 85.8% |
| Textual content edit distance | 0.032 | 0.055 |
- Tables: Outperforms Gemini2.5-Professional in desk parsing accuracy.
- Textual content: Demonstrates decrease textual content edit distance (indicating increased precision).
- Formulation and Structure: Matches or exceeds main fashions in system recognition and doc construction reconstruction.
Deployment and Integration
- Open-Supply: Launched underneath the MIT license, with supply, documentation, and pre-trained fashions accessible on GitHub. The repository offers set up directions for pip, Conda, and Docker-based deployments.
- API and Scripting: Helps versatile job configuration by way of immediate templates. The mannequin can be utilized interactively or inside automated pipelines for batch doc processing.
- Output Codecs: Extracted outcomes are provided in structured JSON for programmatic use, with choices for Markdown and HTML the place acceptable. Visualization scripts allow inspection of detected layouts.
Conclusion
dots.ocr offers a technical answer for high-accuracy, multilingual doc parsing by unifying format detection and content material recognition in a single, open-source mannequin. It’s notably fitted to situations requiring sturdy, language-agnostic doc evaluation and structured info extraction in resource-constrained or manufacturing environments.
Try the GitHub Page. Be at liberty to take a look at our GitHub Page for Tutorials, Codes and Notebooks. Additionally, be happy to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our Newsletter.

Michal Sutter is an information science skilled with a Grasp of Science in Knowledge Science from the College of Padova. With a stable basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at reworking complicated datasets into actionable insights.