
Liquid AI has launched LFM2.5, a brand new era of small basis fashions constructed on the LFM2 structure and centered at on machine and edge deployments. The mannequin household contains LFM2.5-1.2B-Base and LFM2.5-1.2B-Instruct and extends to Japanese, imaginative and prescient language, and audio language variants. It’s launched as open weights on Hugging Face and uncovered via the LEAP platform.
Structure and coaching recipe
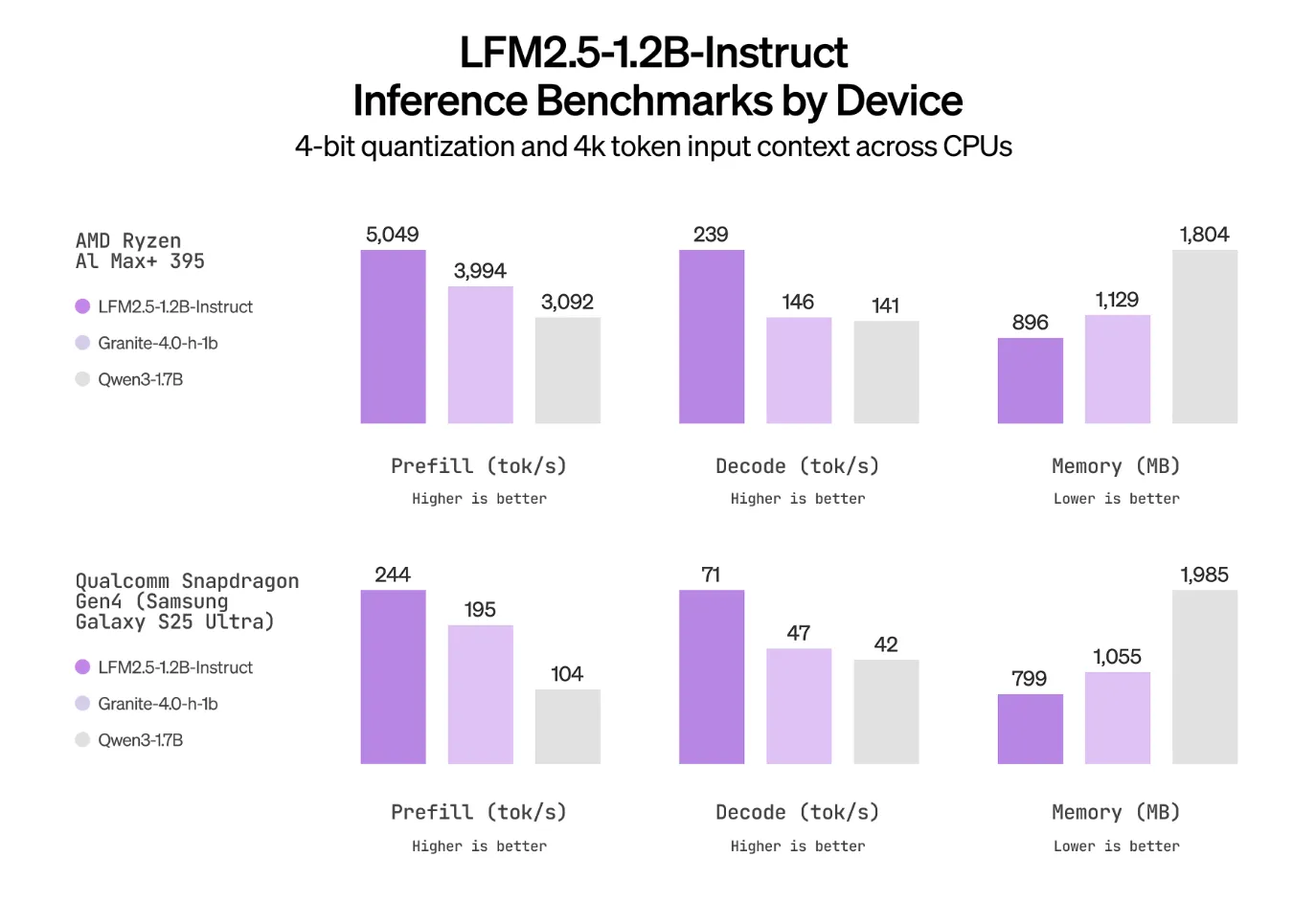
LFM2.5 retains the hybrid LFM2 structure that was designed for quick and reminiscence environment friendly inference on CPUs and NPUs and scales the information and publish coaching pipeline. Pretraining for the 1.2 billion parameter spine is prolonged from 10T to 28T tokens. The instruct variant then receives supervised effective tuning, choice alignment, and enormous scale multi stage reinforcement studying centered on instruction following, device use, math, and data reasoning.
Textual content mannequin efficiency at one billion scale
LFM2.5-1.2B-Instruct is the primary common function textual content mannequin. Liquid AI group studies benchmark outcomes on GPQA, MMLU Professional, IFEval, IFBench, and a number of other operate calling and coding suites. The mannequin reaches 38.89 on GPQA and 44.35 on MMLU Professional. Competing 1B class open fashions reminiscent of Llama-3.2-1B Instruct and Gemma-3-1B IT rating considerably decrease on these metrics.
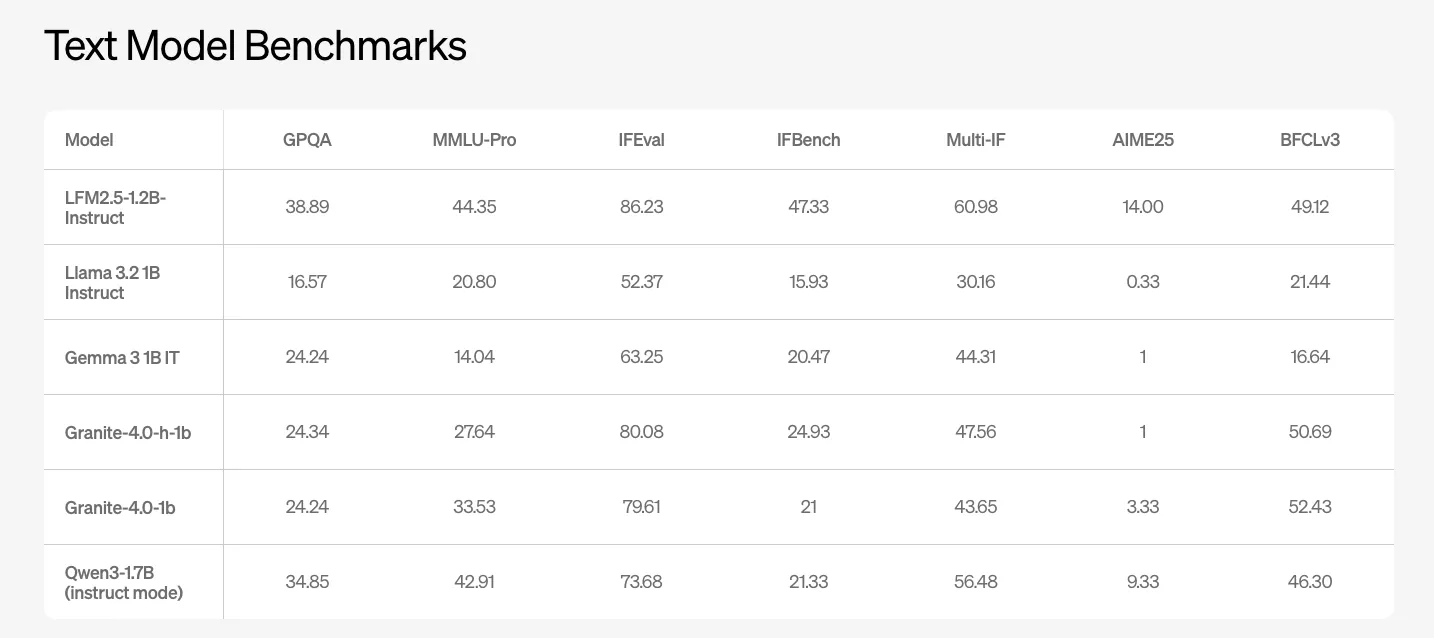
On IFEval and IFBench, which goal multi step instruction following and performance calling high quality, LFM2.5-1.2B-Instruct studies 86.23 and 47.33. These values are forward of the opposite 1B class baselines within the above Liquid AI desk.
Japanese optimized variant
LFM2.5-1.2B-JP is a Japanese optimized textual content mannequin derived from the identical spine. It targets duties reminiscent of JMMLU, M-IFEval in Japanese, and GSM8K in Japanese. This checkpoint improves over the final instruct mannequin on Japanese duties and competes with or surpasses different small multilingual fashions like Qwen3-1.7B, Llama 3.2-1B Instruct, and Gemma 3-1B IT on these localized benchmarks.
Imaginative and prescient language mannequin for multimodal edge workloads
LFM2.5-VL-1.6B is the up to date imaginative and prescient language mannequin within the sequence. It makes use of LFM2.5-1.2B-Base because the language spine and provides a imaginative and prescient tower for picture understanding. The mannequin is tuned on a variety of visible reasoning and OCR benchmarks, together with MMStar, MM IFEval, BLINK, InfoVQA, OCRBench v2, RealWorldQA, MMMU, and multilingual MMBench. LFM2.5-VL-1.6B improves over the earlier LFM2-VL-1.6B on most metrics and is meant for actual world duties reminiscent of doc understanding, person interface studying, and multi picture reasoning underneath edge constraints.
Audio language mannequin with native speech era
LFM2.5-Audio-1.5B is a local audio language mannequin that helps each textual content and audio inputs and outputs. It’s offered as an Audio to Audio mannequin and makes use of an audio detokenizer that’s described as eight instances quicker than the earlier Mimi based mostly detokenizer on the identical precision on constrained {hardware}.
The mannequin helps two essential era modes. Interleaved era is designed for actual time speech to speech conversational brokers the place latency dominates. Sequential era is aimed toward duties reminiscent of computerized speech recognition and textual content to speech and permits switching the generated modality with out reinitializing the mannequin. The audio stack is educated with quantization conscious coaching at low precision, which retains metrics reminiscent of STOI and UTMOS near the total precision baseline whereas enabling deployment on units with restricted compute.
Key Takeaways
- LFM2.5 is a 1.2B scale hybrid mannequin household constructed on the LFM2 machine optimized structure, with Base, Instruct, Japanese, Imaginative and prescient Language, and Audio Language variants, all launched as open weights on Hugging Face and LEAP.
- Pretraining for LFM2.5 extends from 10T to 28T tokens and the Instruct mannequin provides supervised effective tuning, choice alignment, and enormous scale multi stage reinforcement studying, which pushes instruction following and power use high quality past different 1B class baselines.
- LFM2.5-1.2B-Instruct delivers sturdy textual content benchmark efficiency on the 1B scale, reaching 38.89 on GPQA and 44.35 on MMLU Professional and main peer fashions reminiscent of Llama 3.2 1B Instruct, Gemma 3 1B IT, and Granite 4.0 1B on IFEval and IFBench.
- The household contains specialised multimodal and regional variants, with LFM2.5-1.2B-JP attaining state-of-the-art outcomes for Japanese benchmarks at its scale and LFM2.5-VL-1.6B and LFM2.5-Audio-1.5B overlaying imaginative and prescient language and native audio language workloads for edge brokers.
Take a look at the Technical details and Model weights. Additionally, be at liberty to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Take a look at our newest launch of ai2025.dev, a 2025-focused analytics platform that turns mannequin launches, benchmarks, and ecosystem exercise right into a structured dataset you’ll be able to filter, examine, and export
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.