
Kyutai has launched Hibiki-Zero, a brand new mannequin for simultaneous speech-to-speech translation (S2ST) and speech-to-text translation (S2TT). The system interprets supply speech right into a goal language in real-time. It handles non-monotonic phrase dependencies throughout the course of. Not like earlier fashions, Hibiki-Zero doesn’t require word-level aligned information for coaching. This eliminates a serious bottleneck in scaling AI translation to extra languages.
Conventional approaches depend on supervised coaching with word-level alignments. These alignments are troublesome to gather at scale. Builders normally rely on artificial alignments and language-specific heuristics. Hibiki-Zero removes this complexity by utilizing a novel reinforcement studying (RL) technique to optimize latency.
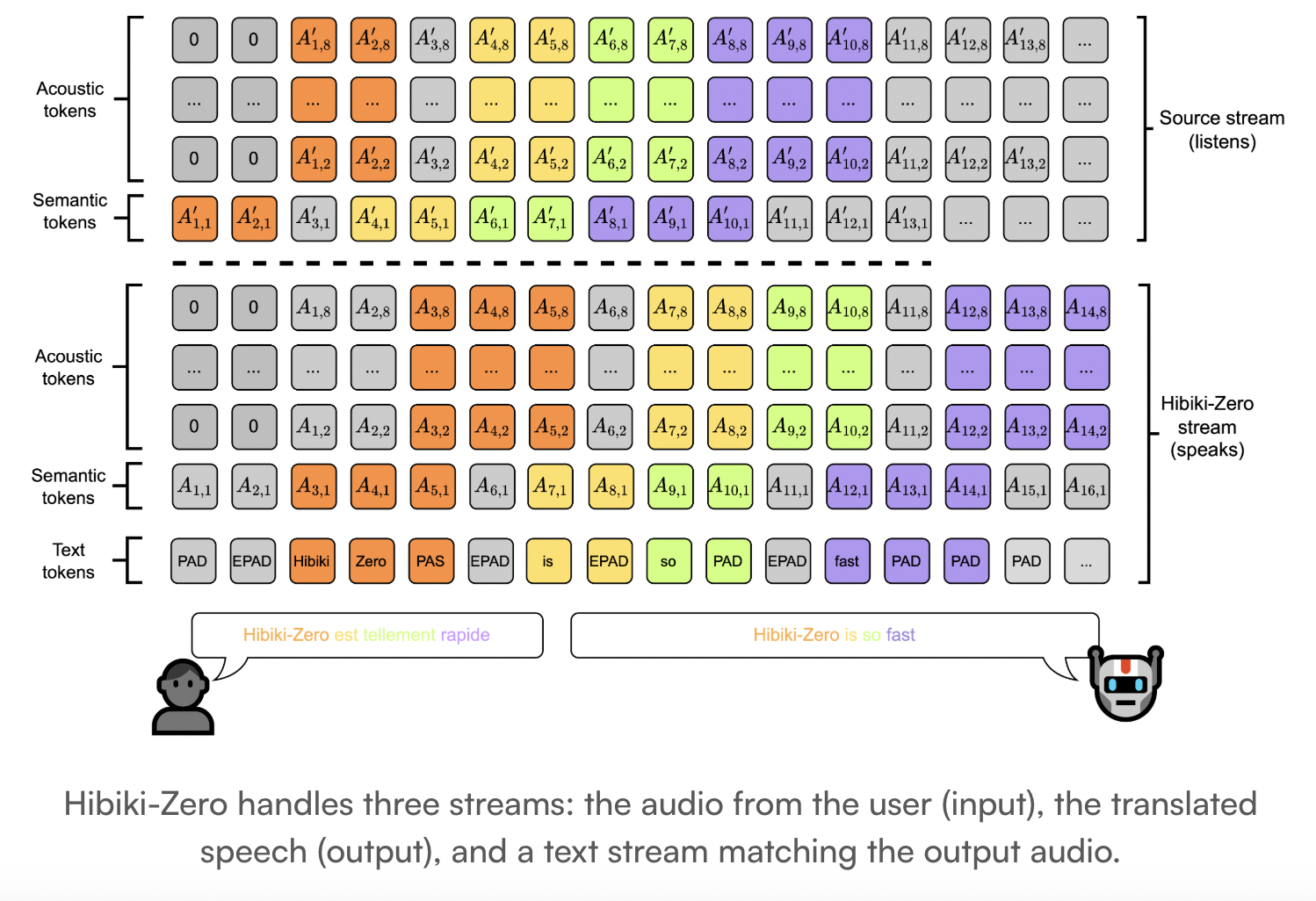
A Multistream Structure
Hibiki-Zero is a decoder-only mannequin. It makes use of a multistream structure to mannequin sequences of tokens collectively. The mannequin handles 3 particular streams:
- Supply Stream: Audio tokens from the enter speech.
- Goal Stream: Generated audio tokens for the translated speech.
- Interior Monologue: A stream of padded textual content tokens that match the goal audio.
The system makes use of the Mimi neural audio codec. Mimi is a causal and streaming codec that encodes waveforms into discrete tokens. It operates at a framerate of 12.5 Hz. The mannequin makes use of an RQ-Transformer to mannequin these audio streams.
The architectural specs embrace:
- Complete Parameters: 3B.
- Temporal Transformer: 28 layers with a latent dimension of 2048.
- Depth Transformer: 6 layers per codebook with a latent dimension of 1024.
- Context Window: 4min.
- Audio Codebooks: 16 ranges for high-quality speech.
Coaching With out Human Interpretation Knowledge
Hibiki-Zero is skilled in 2 foremost levels:
- Coarse Alignment Coaching: The mannequin first trains on sentence-level aligned information. This information ensures that the ith sentence within the goal is a translation of the ith sentence within the supply. The analysis crew use a method to insert synthetic silence within the goal speech to delay its content material relative to the supply.
- Reinforcement Studying (RL): The mannequin makes use of Group Relative Coverage Optimization (GRPO) to refine its coverage. This stage reduces translation latency whereas preserving high quality.
The RL course of makes use of course of rewards primarily based solely on the BLEU rating. It computes intermediate rewards at a number of factors throughout translation. A hyperparameter ⍺ balances the trade-off between velocity and accuracy. A decrease ⍺ reduces latency however could barely lower high quality.
Scaling to Italian in Document Time
The researchers demonstrated how simply Hibiki-Zero adapts to new languages. They added Italian as an enter language utilizing lower than 1000h of speech information.
- They carried out supervised fine-tuning adopted by the GRPO course of.
- The mannequin reached a high quality and latency trade-off much like Meta’s Seamless mannequin.
- It surpassed Seamless in speaker similarity by over 30 factors.
Efficiency and Outcomes
Hibiki-Zero achieves state-of-the-art outcomes throughout 5 X-to-English duties. It was examined on the Audio-NTREX-4L long-form benchmark, which incorporates 15h of speech per TTS system.
| Metric | Hibiki-Zero (French) | Seamless (French) |
| ASR-BLEU (↑) | 28.7 | 23.9 |
| Speaker Similarity (↑) | 61.3 | 44.4 |
| Common Lag (LAAL) (↓) | 2.3 | 6.2 |
Briefly-form duties (Europarl-ST), Hibiki-Zero reached an ASR-BLEU of 34.6 with a lag of 2.8 seconds. Human raters additionally scored the mannequin considerably greater than baselines for speech naturalness and voice switch.

Key Takeaways
- Zero Aligned Knowledge Requirement: Hibiki-Zero eliminates the necessity for costly, hand-crafted word-level alignments between supply and goal speech, which had been beforehand the largest bottleneck in scaling simultaneous translation to new languages.
- GRPO-Pushed Latency Optimization: The mannequin makes use of Group Relative Coverage Optimization (GRPO) and a easy reward system primarily based solely on BLEU scores to routinely study an environment friendly translation coverage, balancing excessive translation high quality with low latency.
- Coarse-to-Tremendous Coaching Technique: The coaching pipeline begins with sentence-level aligned information to show the mannequin base translation at excessive latency, adopted by a reinforcement studying part that “teaches” the mannequin when to talk and when to hear.
- Superior Voice and Naturalness: In benchmarking towards earlier state-of-the-art programs like Seamless, Hibiki-Zero achieved a 30-point lead in speaker similarity and considerably greater scores in speech naturalness and audio high quality throughout 5 language duties.
- Speedy New Language Adaptation: The structure is extremely transportable; researchers demonstrated that Hibiki-Zero may very well be tailored to a brand new enter language (Italian) with lower than 1,000 hours of speech information whereas sustaining its unique efficiency on different languages.
Try the Paper, Technical details, Repo and Samples. Additionally, be happy to comply with us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
