 Mannequin Powering Enterprise Speech Intelligence")
Within the panorama of enterprise AI, the bridge between unstructured audio and actionable textual content has usually been a bottleneck of proprietary APIs and complicated cascaded pipelines. As we speak, Cohere—an organization historically identified for its text-generation and embedding fashions—has formally stepped into the Automated Speech Recognition (ASR) market with the discharge of their newest mannequin ‘Cohere Transcribe‘.
The Structure: Why Conformer Issues
To know the Cohere Transcribe mannequin, one should look previous the ‘Transformer’ label. Whereas the mannequin is an encoder-decoder structure, it particularly makes use of a giant Conformer encoder paired with a light-weight Transformer decoder.
A Conformer is a hybrid structure that mixes the strengths of Convolutional Neural Networks (CNNs) and Transformers. In ASR, native options (like particular phonemes or fast transitions in sound) are sometimes dealt with higher by CNNs, whereas international context (the that means of the sentence) is the area of Transformers. By interleaving these layers, Cohere’s mannequin is designed to seize each fine-grained acoustic particulars and long-range linguistic dependencies.
The mannequin was educated utilizing commonplace supervised cross-entropy, a traditional however sturdy coaching goal that focuses on minimizing the distinction between the anticipated textual content and the ground-truth transcript.
Efficiency
Whereas some international fashions intention for 100+ languages with various levels of accuracy, Cohere has opted for a ‘high quality over amount’ method. The mannequin formally helps 14 languages: English, German, French, Italian, Spanish, Portuguese, Greek, Dutch, Polish, Arabic, Vietnamese, Chinese language, Japanese, and Korean.
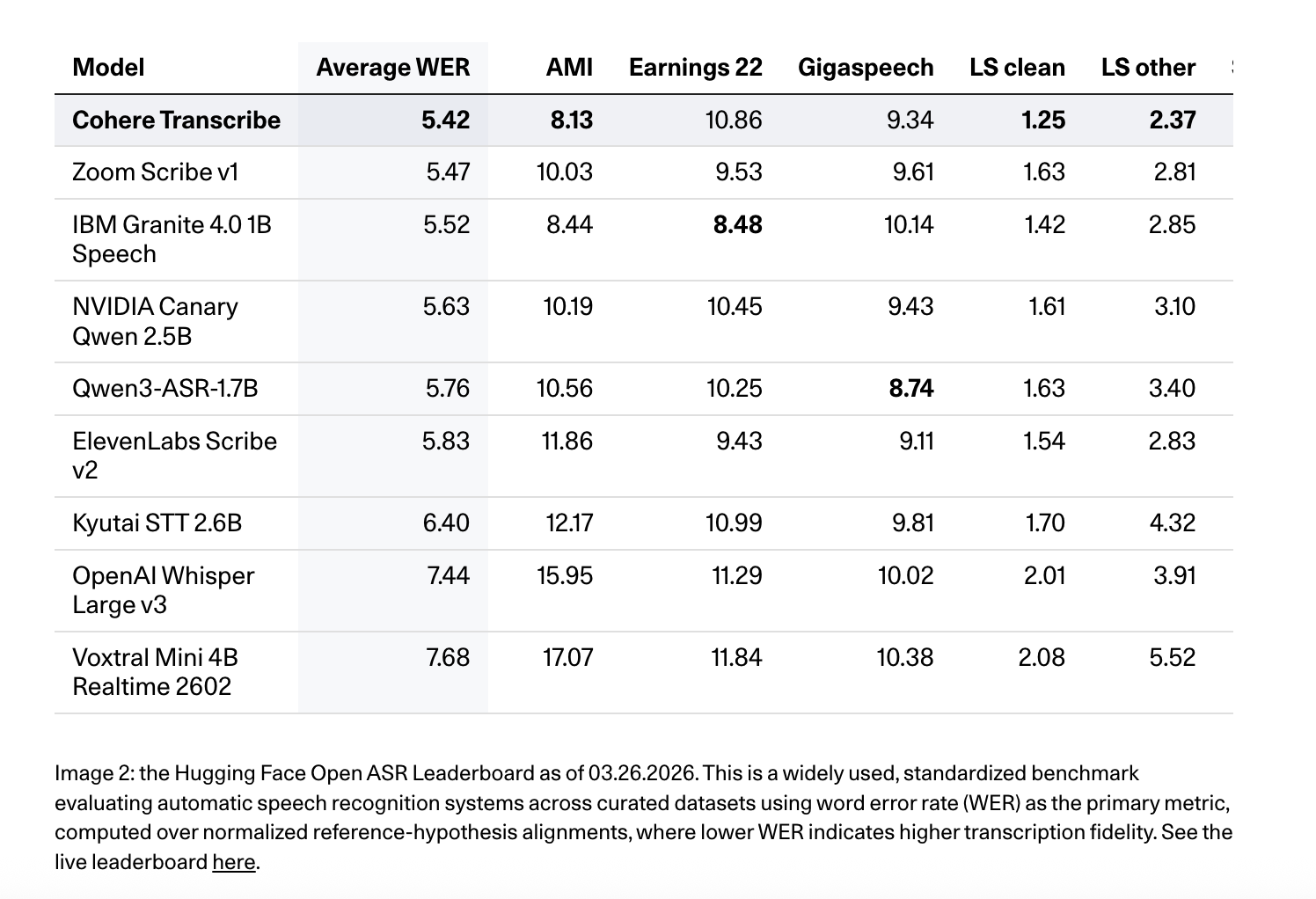
Cohere positions Transcribe as a high-accuracy, production-oriented ASR mannequin. It ranks #1 on the Hugging Face Open ASR Leaderboard (March 26, 2026) with an common WER of 5.42% throughout benchmark units together with AMI, Earnings22, GigaSpeech, LibriSpeech clear/different, SPGISpeech, TED-LIUM, and VoxPopuli. It additionally scores 8.13 on AMI, 10.86 on Earnings22, 9.34 on GigaSpeech, 1.25 on LibriSpeech clear, 2.37 on LibriSpeech different, 3.08 on SPGISpeech, 2.49 on TED-LIUM, and 5.87 on VoxPopuli, outperforming fashions resembling Whisper Giant v3 (7.44 common WER), ElevenLabs Scribe v2 (5.83), and Qwen3-ASR-1.7B (5.76) on varied leaderboards.
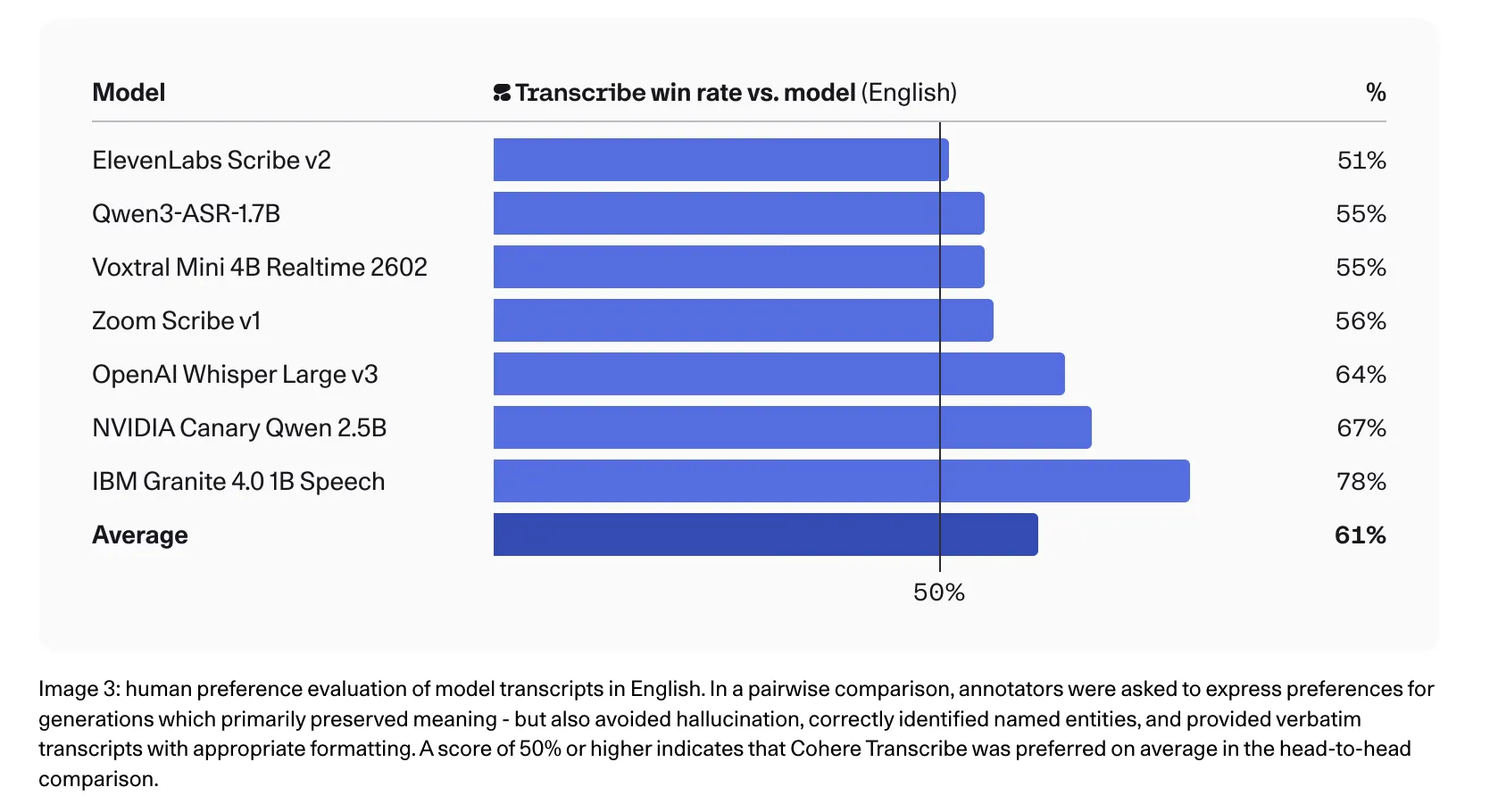
Cohere workforce additionally stories stronger human choice leads to English, the place annotators most popular Transcribe over competing transcripts in head-to-head comparisons, together with 78% in opposition to IBM Granite 4.0 1B Speech, 67% in opposition to NVIDIA Canary Qwen 2.5B, 64% in opposition to Whisper Giant v3, and 56% in opposition to Zoom Scribe v1.
Lengthy-Type Audio: The 35-Second Rule
Dealing with long-form audio—resembling 60-minute earnings calls or authorized proceedings—presents a novel problem for memory-intensive architectures. Cohere addresses this not by sliding-window consideration, however by a strong chunking and reassembly logic.
The mannequin is natively designed to course of audio in 35-second segments. For any file exceeding this restrict, the system routinely:
- Splits the audio into overlapping chunks.
- Processes every section by the Conformer-Transformer pipeline.
- Reassembles the overlapping textual content to make sure continuity.
This method ensures that the mannequin can deal with a 55-minute file with out exhausting GPU VRAM, offered the engineering pipeline manages the chunking orchestration appropriately.
Key Takeaways
- State-of-the-Artwork Accuracy: The mannequin launched at #1 on the Hugging Face Open ASR Leaderboard (March 26, 2026) with a median Phrase Error Charge (WER) of 5.42%. It outperforms established fashions like Whisper Giant v3 (7.44%) and IBM Granite 4.0 (5.52%) throughout benchmarks together with LibriSpeech, Earnings22, and TED-LIUM.
- Hybrid Conformer Structure: In contrast to commonplace pure-Transformer fashions, Transcribe makes use of a giant Conformer encoder paired with a light-weight Transformer decoder. This hybrid design permits the mannequin to effectively seize each native acoustic options (by way of convolution) and international linguistic context (by way of self-attention).
- Automated Lengthy-Type Dealing with: To keep up reminiscence effectivity and stability, the mannequin makes use of a local 35-second chunking logic. It routinely segments audio longer than 35 seconds into overlapping chunks and reassembles them, permitting it to course of prolonged recordings—like 55-minute earnings calls—with out efficiency degradation.
- Outlined Technical Constraints: The mannequin is a pure ASR instrument and doesn’t natively characteristic speaker diarization or timestamps. It helps 14 particular languages and performs greatest when the goal language is pre-defined, because it doesn’t embrace express automated language detection or optimized assist for code-switching.
Try the Technical details and Model Weight on HF. Additionally, be happy to comply with us on Twitter and don’t overlook to hitch our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.



