
The Baidu Qianfan Workforce launched Qianfan-OCR, a 4B-parameter end-to-end mannequin designed to unify doc parsing, format evaluation, and doc understanding inside a single vision-language structure. In contrast to conventional multi-stage OCR pipelines that chain separate modules for format detection and textual content recognition, Qianfan-OCR performs direct image-to-Markdown conversion and helps prompt-driven duties like desk extraction and doc query answering.
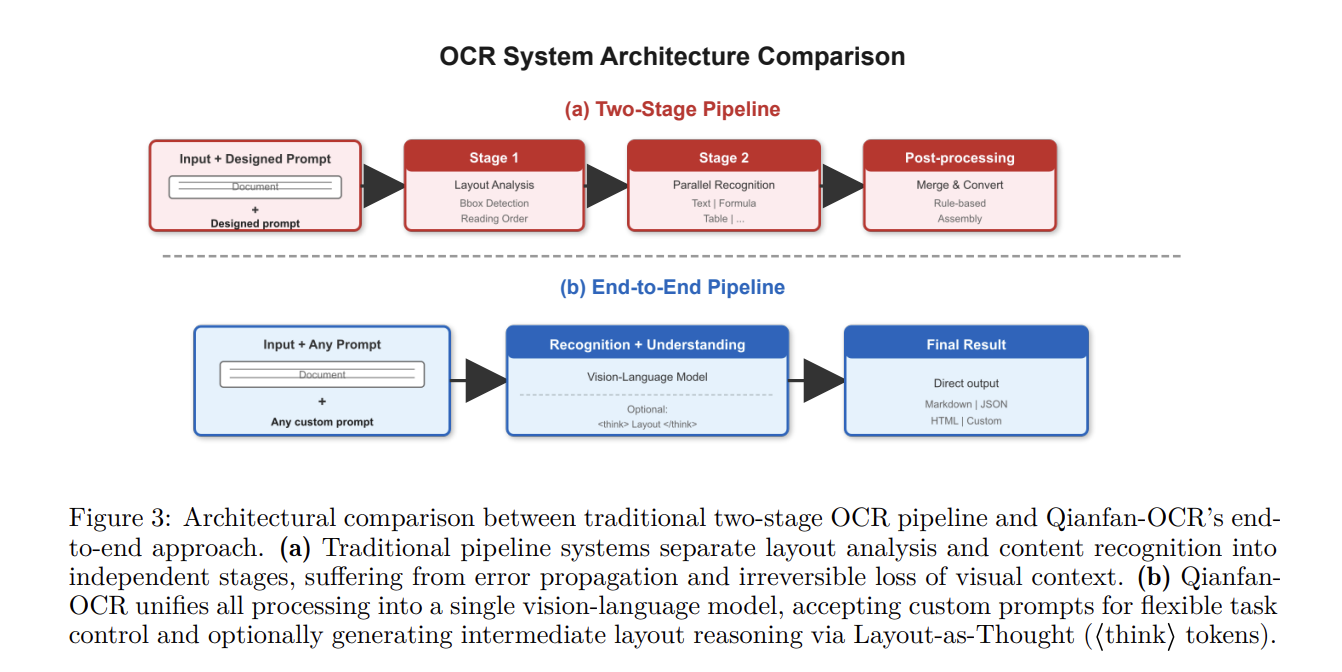
Structure and Technical Specs
Qianfan-OCR makes use of the multimodal bridging structure from the Qianfan-VL framework. The system consists of three main elements:
- Imaginative and prescient Encoder (Qianfan-ViT): Employs an Any Decision design that tiles photographs into 448 x 448 patches. It helps variable-resolution inputs as much as 4K, producing as much as 4,096 visible tokens per picture to take care of spatial decision for small fonts and dense textual content.
- Cross-Modal Adapter: A light-weight two-layer MLP with GELU activation that tasks visible options into the language mannequin’s embedding house.
- Language Mannequin Spine (Qwen3-4B): A 4.0B-parameter mannequin with 36 layers and a local 32K context window. It makes use of Grouped-Question Consideration (GQA) to scale back KV cache reminiscence utilization by 4x.
‘Format-as-Thought’ Mechanism
The principle function of the mannequin is Format-as-Thought, an non-obligatory considering section triggered by
- Purposeful Utility: This course of recovers express format evaluation capabilities (factor localization and sort classification) typically misplaced in end-to-end paradigms.
- Efficiency Traits: Analysis on OmniDocBench v1.5 signifies that enabling the considering section offers a constant benefit on paperwork with excessive “format label entropy”—these containing heterogeneous components like blended textual content, formulation, and diagrams.
- Effectivity: Bounding field coordinates are represented as devoted particular tokens (
Empirical Efficiency and Benchmarks
Qianfan-OCR was evaluated towards each specialised OCR programs and common vision-language fashions (VLMs).
Doc Parsing and Normal OCR
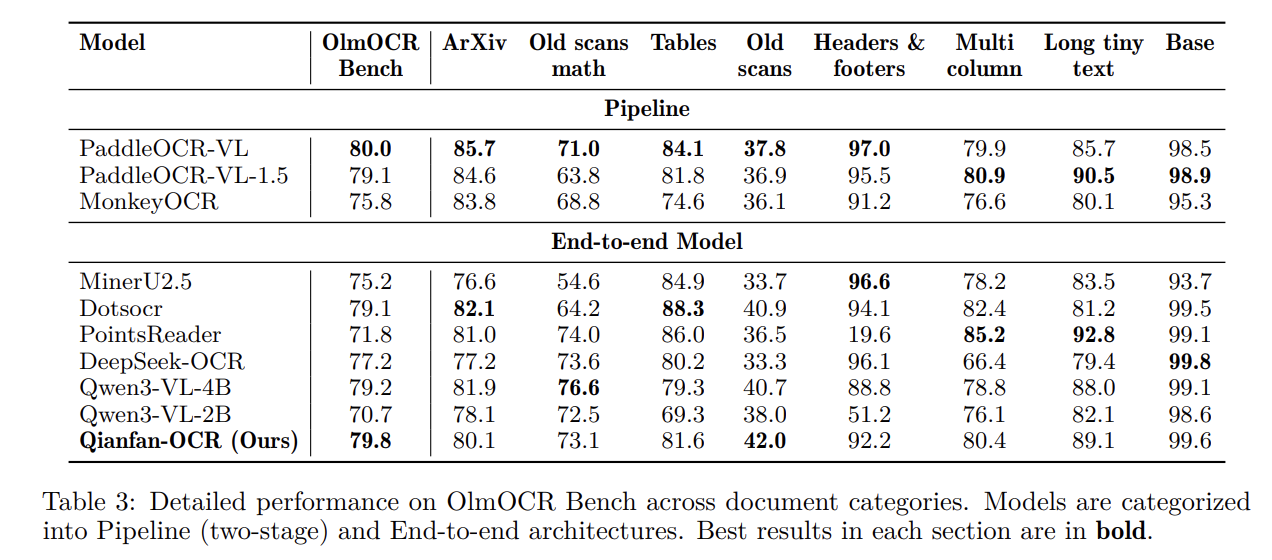
The mannequin ranks first amongst end-to-end fashions on a number of key benchmarks:
- OmniDocBench v1.5: Achieved a rating of 93.12, surpassing DeepSeek-OCR-v2 (91.09) and Gemini-3 Professional (90.33).
- OlmOCR Bench: Scored 79.8, main the end-to-end class.
- OCRBench: Achieved a rating of 880, rating first amongst all examined fashions.
On public KIE benchmarks, Qianfan-OCR achieved the very best common rating (87.9), outperforming considerably bigger fashions.
| Mannequin | General Imply (KIE) | OCRBench KIE | Nanonets KIE (F1) |
| Qianfan-OCR (4B) | 87.9 | 95.0 | 86.5 |
| Qwen3-4B-VL | 83.5 | 89.0 | 83.3 |
| Qwen3-VL-235B-A22B | 84.2 | 94.0 | 83.8 |
| Gemini-3.1-Professional | 79.2 | 96.0 | 76.1 |
Doc Understanding
Comparative testing revealed that two-stage OCR+LLM pipelines typically fail on duties requiring spatial reasoning. As an example, all examined two-stage programs scored 0.0 on CharXiv benchmarks, because the textual content extraction section discards the visible context (axis relationships, knowledge level positions) essential for chart interpretation.
Deployment and Inference
Inference effectivity was measured in Pages Per Second (PPS) utilizing a single NVIDIA A100 GPU.
- Quantization: With W8A8 (AWQ) quantization, Qianfan-OCR achieved 1.024 PPS, a 2x speedup over the W16A16 baseline with negligible accuracy loss.
- Structure Benefit: In contrast to pipeline programs that depend on CPU-based format evaluation—which might change into a bottleneck—Qianfan-OCR is GPU-centric. This avoids inter-stage processing delays and permits for environment friendly large-batch inference.
Try Paper, Repo and Model on HF. Additionally, be happy to observe us on Twitter and don’t neglect to affix our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.

Michal Sutter is a knowledge science skilled with a Grasp of Science in Information Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at remodeling complicated datasets into actionable insights.



