 Introduces Olmo 3: An Open Supply 7B and 32B LLM Household Constructed on the Dolma 3 and Dolci Stack")
Allen Institute for AI (AI2) is releasing Olmo 3 as a totally open mannequin household that exposes all the ‘mannequin movement’, from uncooked information and code to intermediate checkpoints and deployment prepared variants.
Olmo 3 is a dense transformer suite with 7B and 32B parameter fashions. The household consists of Olmo 3-Base, Olmo 3-Assume, Olmo 3-Instruct, and Olmo 3-RL Zero. Each 7B and 32B variants share a context size of 65,536 tokens and use the identical staged coaching recipe.
 Introduces Olmo 3: An Open Supply 7B and 32B LLM Household Constructed on the Dolma 3 and Dolci Stack")
Dolma 3 Knowledge Suite
On the core of the coaching pipeline is Dolma 3, a brand new information assortment designed for Olmo 3. Dolma 3 consists of Dolma 3 Combine, Dolma 3 Dolmino Combine, and Dolma 3 Longmino Combine. Dolma 3 Combine is a 5.9T token pre coaching dataset with net textual content, scientific PDFs, code repositories, and different pure information. The Dolmino and Longmino subsets are constructed from filtered, larger high quality slices of this pool.
Dolma 3 Combine helps the primary pre coaching stage for Olmo 3-Base. AI2 analysis workforce then applies Dolma 3 Dolmino Combine, a 100B token mid coaching set that emphasizes math, code, instruction following, studying comprehension, and considering oriented duties. Lastly, Dolma 3 Longmino Combine provides 50B tokens for the 7B mannequin and 100B tokens for the 32B mannequin, with a robust give attention to lengthy paperwork and scientific PDFs processed with the olmOCR pipeline. This staged curriculum is what pushes the context restrict to 65,536 tokens whereas sustaining stability and high quality.
Giant Scale Coaching on H100 Clusters
Olmo 3-Base 7B trains on Dolma 3 Combine utilizing 1,024 H100 units, reaching about 7,700 tokens per gadget per second. Later levels use 128 H100s for Dolmino mid coaching and 256 H100s for Longmino lengthy context extension.
Base Mannequin Efficiency In opposition to Open Households
On commonplace functionality benchmarks, Olmo 3-Base 32B is positioned as a number one totally open base mannequin. AI2 analysis workforce studies that it’s aggressive with outstanding open weight households reminiscent of Qwen 2.5 and Gemma 3 at comparable sizes. In contrast throughout a large suite of duties, Olmo 3-Base 32B ranks close to or above these fashions whereas preserving the total information and coaching configuration open for inspection and reuse.
Reasoning Centered Olmo 3 Assume
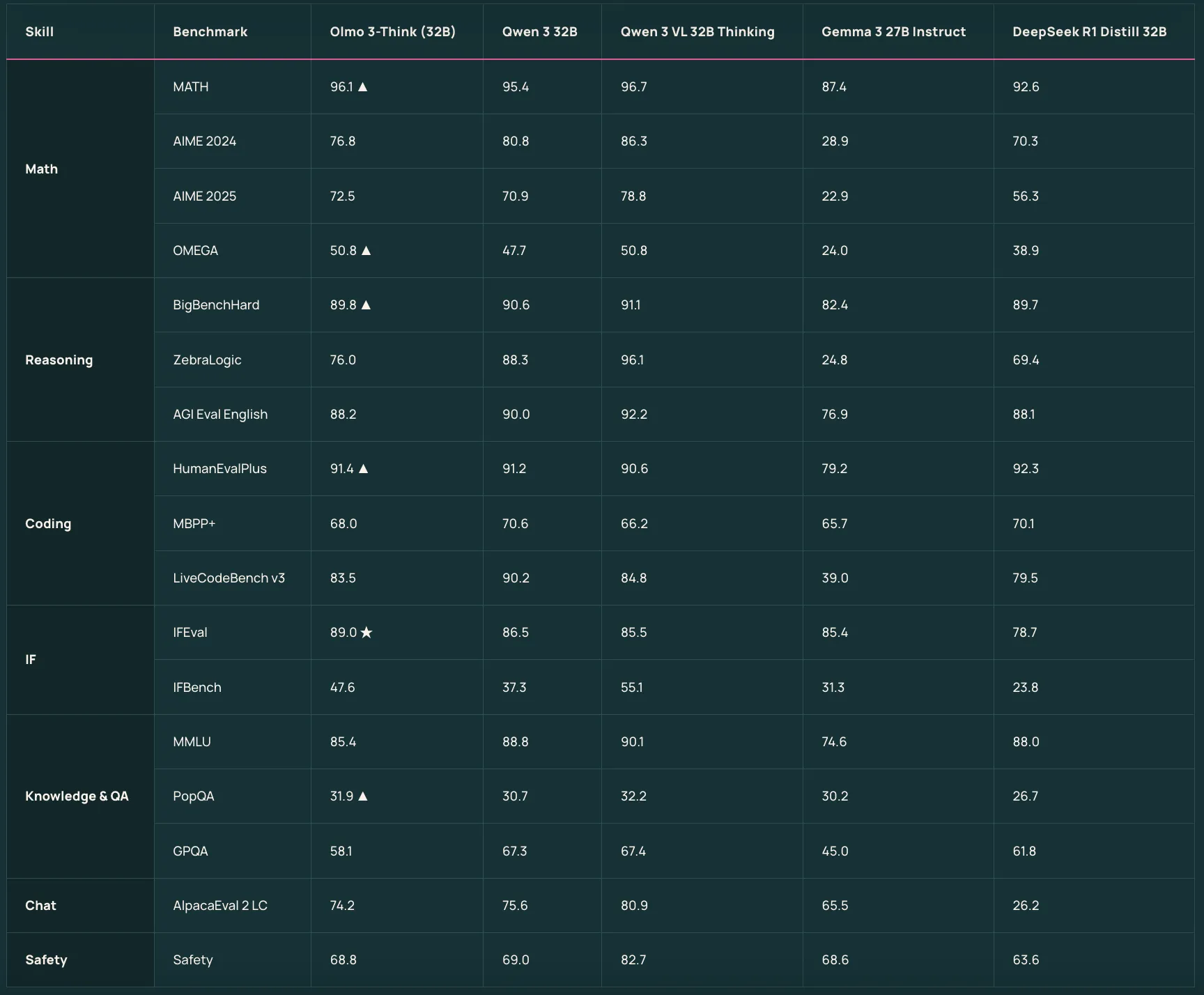
Olmo 3-Assume 7B and Olmo 3-Assume 32B sit on prime of the bottom fashions as reasoning targeted variants. They use a 3 stage publish coaching recipe that features supervised fantastic tuning, Direct Choice Optimization, and Reinforcement Studying with Verifiable Rewards inside the OlmoRL framework. Olmo 3-Assume 32B is described because the strongest totally open reasoning mannequin and it narrows the hole to Qwen 3 32B considering fashions whereas utilizing about six occasions fewer coaching tokens.
Olmo 3 Instruct for Chat and Instrument Use
Olmo 3-Instruct 7B is tuned for quick instruction following, multi flip chat, and gear use. It begins from Olmo 3-Base 7B and applies a separate Dolci Instruct information and coaching pipeline that covers supervised fantastic tuning, DPO, and RLVR for conversational and performance calling workloads. AI2 analysis workforce studies that Olmo 3-Instruct matches or outperforms open weight opponents reminiscent of Qwen 2.5, Gemma 3, and Llama 3.1 and is aggressive with Qwen 3 households at comparable scales for a number of instruction and reasoning benchmarks.
RL Zero for Clear RL Analysis
Olmo 3-RL Zero 7B is designed for researchers who care about reinforcement studying on language fashions however want clear separation between pre coaching information and RL information. It’s constructed as a totally open RL pathway on prime of Olmo 3-Base and makes use of Dolci RL Zero datasets which might be decontaminated with respect to Dolma 3.
Comparability Desk
| Mannequin variant | Coaching or publish coaching information | Major use case | Reported place vs different open fashions |
|---|---|---|---|
| Olmo 3 Base 7B | Dolma 3 Combine pre coaching, Dolma 3 Dolmino Combine mid coaching, Dolma 3 Longmino Combine lengthy context | Normal basis mannequin, lengthy context reasoning, code, math | Robust totally open 7B base, designed as basis for Assume, Instruct, RL Zero, evaluated towards main open 7B scale bases |
| Olmo 3 Base 32B | Identical Dolma 3 staged pipeline as 7B, with 100B Longmino tokens for lengthy context | Excessive finish base for analysis, lengthy context workloads, RL setups | Described as the very best totally open 32B base, corresponding to Qwen 2.5 32B and Gemma 3 27B and outperforming Marin, Apertus, LLM360 |
| Olmo 3 Assume 7B | Olmo 3 Base 7B, plus Dolci Assume SFT, Dolci Assume DPO, Dolci Assume RL in OlmoRL framework | Reasoning targeted 7B mannequin with inside considering traces | Absolutely open reasoning mannequin at environment friendly scale that permits chain of thought analysis and RL experiments on modest {hardware} |
| Olmo 3 Assume 32B | Olmo 3 Base 32B, plus the identical Dolci Assume SFT, DPO, RL pipeline | Flagship reasoning mannequin with lengthy considering traces | Acknowledged because the strongest totally open considering mannequin, aggressive with Qwen 3 32B considering fashions whereas coaching on about 6x fewer tokens |
| Olmo 3 Instruct 7B | Olmo 3 Base 7B, plus Dolci Instruct SFT, Dolci Instruct DPO, Dolci Instruct RL 7B | Instruction following, chat, perform calling, device use | Reported to outperform Qwen 2.5, Gemma 3, Llama 3 and to slim the hole to Qwen 3 households at comparable scale |
| Olmo 3 RL Zero 7B | Olmo 3 Base 7B, plus Dolci RLZero Math, Code, IF, Combine datasets, decontaminated from Dolma 3 | RLVR analysis on math, code, instruction following, blended duties | Launched as a totally open RL pathway for benchmarking RLVR on prime of a base mannequin with totally open pre coaching information |
Key Takeaways
- Finish to finish clear pipeline: Olmo 3 exposes the total ‘mannequin movement’ from Dolma 3 information development, by means of staged pre coaching and publish coaching, to launched checkpoints, analysis suites, and tooling, enabling totally reproducible LLM analysis and fantastic grained debugging.
- Dense 7B and 32B fashions with 65K context: The household covers 7B and 32B dense transformers, all with a 65,536 token context window, skilled by way of a 3 stage Dolma 3 curriculum, Dolma 3 Combine for predominant pre coaching, Dolma 3 Dolmino for mid coaching, and Dolma 3 Longmino for lengthy context extension.
- Robust open base and reasoning fashions: Olmo 3 Base 32B is positioned as a prime totally open base mannequin at its scale, aggressive with Qwen 2.5 and Gemma 3, whereas Olmo 3 Assume 32B is described because the strongest totally open considering mannequin and approaches Qwen 3 32B considering fashions utilizing about 6 occasions fewer coaching tokens.
- Process tuned Instruct and RL Zero variants: Olmo 3 Instruct 7B targets instruction following, multi flip chat, and gear use utilizing Dolci Instruct SFT, DPO, and RLVR information, and is reported to match or outperform Qwen 2.5, Gemma 3, and Llama 3.1 at comparable scale. Olmo 3 RL Zero 7B offers a totally open RLVR pathway with Dolci RLZero datasets decontaminated from pre coaching information for math, code, instruction following, and basic chat.
Olmo 3 is an uncommon launch as a result of it operationalizes openness throughout the total stack, Dolma 3 information recipes, staged pre coaching, Dolci publish coaching, RLVR in OlmoRL, and analysis with OLMES and OlmoBaseEval. This reduces ambiguity round information high quality, lengthy context coaching, and reasoning oriented RL, and it creates a concrete baseline for extending Olmo 3 Base, Olmo 3 Assume, Olmo 3 Instruct, and Olmo 3 RL Zero in managed experiments. Total, Olmo 3 units a rigorous reference level for clear, analysis grade LLM pipelines.
Try the Technical details. Be happy to take a look at our GitHub Page for Tutorials, Codes and Notebooks. Additionally, be happy to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.

Michal Sutter is a knowledge science skilled with a Grasp of Science in Knowledge Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and information engineering, Michal excels at reworking advanced datasets into actionable insights.