
Alibaba’s Tongyi Lab has open-sourced Tongyi-DeepResearch-30B-A3B, an agent-specialized massive language mannequin constructed for long-horizon, deep information-seeking with net instruments. The mannequin makes use of a mixture-of-experts (MoE) design with ~30.5B complete parameters and ~3–3.3B lively per token, enabling excessive throughput whereas preserving sturdy reasoning efficiency. It targets multi-turn analysis workflows—looking out, shopping, extracting, cross-checking, and synthesizing proof—underneath ReAct-style software use and a heavier test-time scaling mode. The discharge contains weights (Apache-2.0), inference scripts, and analysis utilities.
What the benchmarks present?
Tongyi DeepResearch experiences state-of-the-art outcomes on agentic search suites regularly used to check “deep analysis” brokers:
- Humanity’s Final Examination (HLE): 32.9,
- BrowseComp: 43.4 (EN) and 46.7 (ZH),
- xbench-DeepSearch: 75,
with extra sturdy outcomes throughout WebWalkerQA, GAIA, FRAMES, and SimpleQA. The staff finds the system as on par with OpenAI-style deep analysis brokers and “systematically outperforming current proprietary and open-source” brokers throughout these duties.
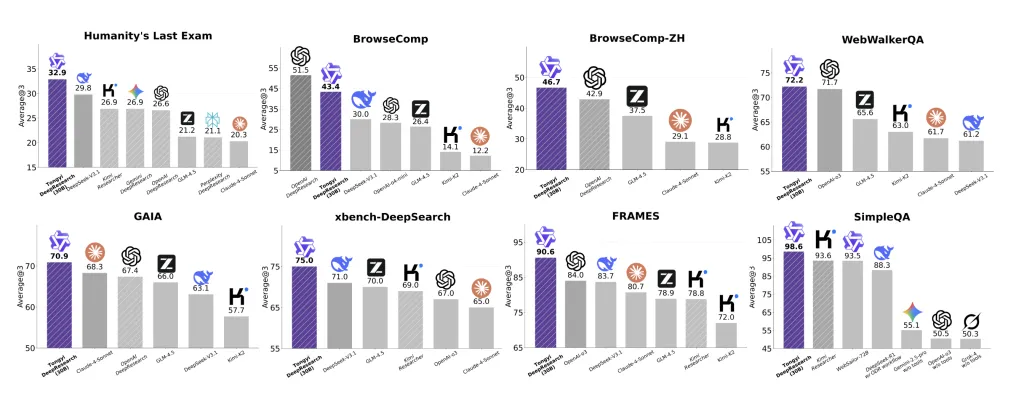
Structure and inference profile
- MoE routing (Qwen3-MoE lineage) with ≈30.5B complete / ≈3.3B lively parameters, giving the price envelope of a small dense mannequin whereas retaining specialist capability.
- Context size: 128K tokens, appropriate for lengthy, tool-augmented shopping classes and iterative synthesis.
- Twin inference modes:
- ReAct (native) for direct analysis of intrinsic reasoning and gear use,
- IterResearch “Heavy” mode for test-time scaling with structured multi-round synthesis/reconstruction of context to scale back noise accumulation.
Coaching pipeline: artificial information + on-policy RL
Tongyi DeepResearch is skilled end-to-end as an agent, not only a chat LLM, utilizing a completely automated, scalable information engine:
- Agentic continuous pre-training (CPT): large-scale artificial trajectories constructed from curated corpora, historic software traces, and graph-structured data to show retrieval, shopping, and multi-source fusion.
- Agentic SFT cold-start: trajectories in ReAct and IterResearch codecs for schema-consistent planning and gear use.
- On-policy RL with Group Relative Coverage Optimization (GRPO), token-level coverage gradients, leave-one-out benefit estimation, and negative-sample filtering to stabilize studying in non-stationary net environments.
Function in doc and net analysis workflows
Deep-research duties stress 4 capabilities: (1) long-horizon planning, (2) iterative retrieval and verification throughout sources, (3) proof monitoring with low hallucination charges, and (4) synthesis underneath massive contexts. The IterResearch rollout restructures context every “spherical,” retaining solely important artifacts to mitigate context bloat and error propagation, whereas the ReAct baseline demonstrates that the behaviors are realized quite than prompt-engineered. The reported scores on HLE and BrowseComp recommend improved robustness on multi-hop, tool-mediated queries the place prior brokers typically over-fit to immediate patterns or saturate at low depths.
Key options of Tongyi DeepResearch-30B-A3B
- MoE effectivity at scale: ~30.5B complete parameters with ~3.0–3.3B activated per token (Qwen3-MoE lineage), enabling small-model inference value with large-model capability.
- 128K context window: long-horizon rollouts with proof accumulation for multi-step net analysis.
- Twin inference paradigms: native ReAct for intrinsic tool-use analysis and IterResearch “Heavy” (test-time scaling) for deeper multi-round synthesis.
- Automated agentic information engine: absolutely automated synthesis pipeline powering agentic continuous pre-training (CPT), supervised fine-tuning (SFT), and RL.
- On-policy RL with GRPO: Group Relative Coverage Optimization with token-level coverage gradients, leave-one-out benefit estimation, and selective negative-sample filtering for stability.
- Reported SOTA on deep-research suites: HLE 32.9, BrowseComp 43.4 (EN) / 46.7 (ZH), xbench-DeepSearch 75; sturdy outcomes on WebWalkerQA/GAIA/FRAMES/SimpleQA.
Abstract
Tongyi DeepResearch-30B-A3B packages a MoE (~30B complete, ~3B lively) structure, 128K context, twin ReAct/IterResearch rollouts, and an automatic agentic information + GRPO RL pipeline right into a reproducible open-source stack. For groups constructing long-horizon analysis brokers, it affords a sensible stability of inference value and functionality with reported sturdy efficiency on deep-research benchmarks
Try the Models on Hugging Face, GitHub Page and Technical details. Be happy to take a look at our GitHub Page for Tutorials, Codes and Notebooks. Additionally, be happy to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.