
Trendy massive language fashions (LLMs) have moved far past easy textual content technology. Lots of the most promising real-world functions now require these fashions to make use of exterior instruments—like APIs, databases, and software program libraries—to unravel complicated duties. However how can we actually know if an AI agent can plan, motive, and coordinate throughout instruments the best way a human assistant would? That is the query MCP-Bench units out to reply.
The Downside with Present Benchmarks
Most earlier benchmarks for tool-using LLMs centered on one-off API calls or slender, artificially stitched workflows. Even the extra superior evaluations not often examined how effectively brokers may uncover and chain the suitable instruments from fuzzy, real-world directions—not to mention whether or not they may coordinate throughout a number of domains and floor their solutions in precise proof. In follow, which means that many fashions carry out effectively on synthetic duties, however battle with the complexity and ambiguity of real-world situations.

What Makes MCP-Bench Totally different
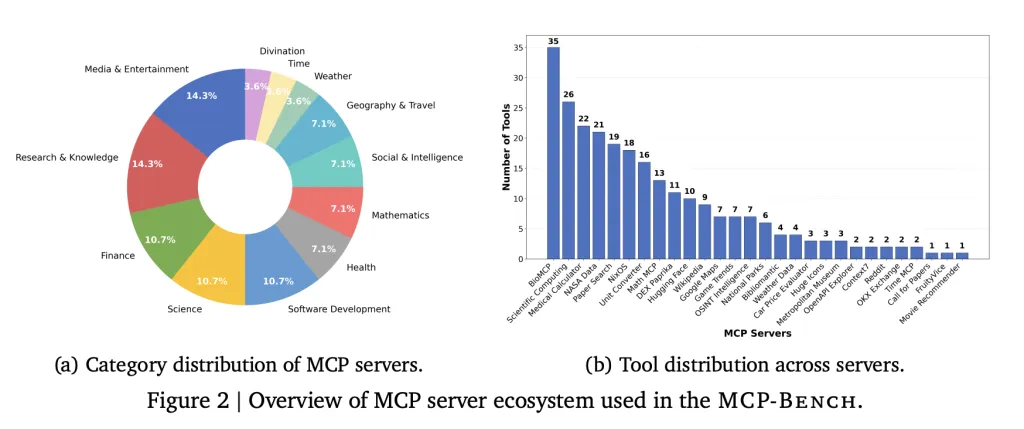
A staff of researchers from Accenture introduce MCP-Bench, a Mannequin Context Protocol (MCP) based mostly benchmark for LLM brokers that straight connects them to twenty-eight real-world servers, every providing a set of instruments throughout varied domains—similar to finance, scientific computing, healthcare, journey, and tutorial analysis. In whole, the benchmark covers 250 instruments, organized in order that practical workflows require each sequential and parallel instrument use, generally throughout a number of servers.
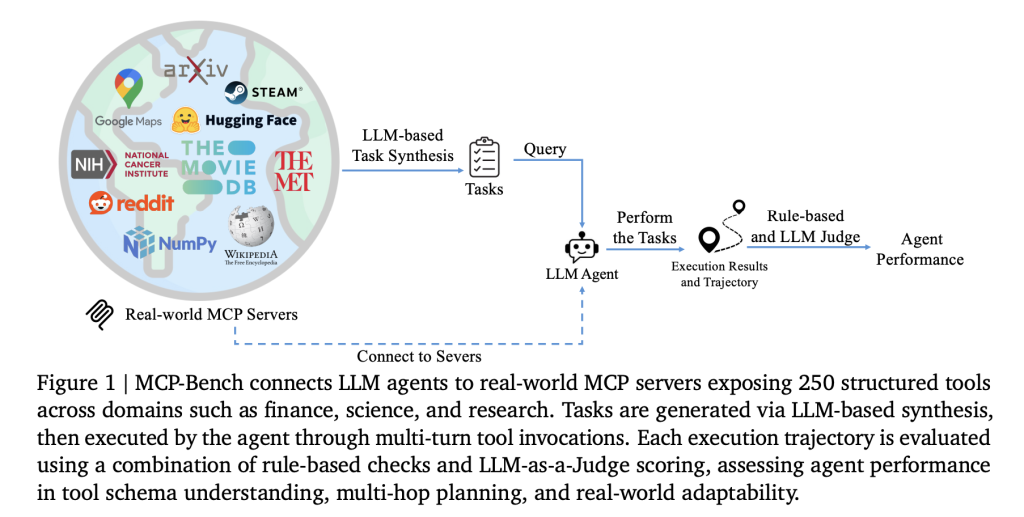
Key options:
- Genuine duties: Duties are designed to replicate actual consumer wants, similar to planning a multi-stop tenting journey (involving geospatial, climate, and park data), conducting biomedical analysis, or changing models in scientific calculations.
- Fuzzy directions: Fairly than specifying instruments or steps, duties are described in pure, generally imprecise language—requiring the agent to deduce what to do, very similar to a human assistant would.
- Instrument variety: The benchmark consists of every thing from medical calculators and scientific computing libraries to monetary analytics, icon collections, and even area of interest instruments like I Ching divination providers.
- High quality management: Duties are mechanically generated, then filtered for solvability and real-world relevance. Every activity additionally is available in two kinds: a exact technical description (used for analysis) and a conversational, fuzzy model (what the agent sees).
- Multi-layered analysis: Each automated metrics (like “did the agent use the proper instrument and supply the suitable parameters?”) and LLM-based judges (to evaluate planning, grounding, and reasoning) are used.
How Brokers Are Examined
An agent working MCP-Bench receives a activity (e.g., “Plan a tenting journey to Yosemite with detailed logistics and climate forecasts”) and should determine, step-by-step, which instruments to name, in what order, and how one can use their outputs. These workflows can span a number of rounds of interplay, with the agent synthesizing outcomes right into a coherent, evidence-backed reply.
Every agent is evaluated on a number of dimensions, together with:
- Instrument choice: Did it select the suitable instruments for every a part of the duty?
- Parameter accuracy: Did it present full and proper inputs to every instrument?
- Planning and coordination: Did it deal with dependencies and parallel steps correctly?
- Proof grounding: Does its remaining reply straight reference the outputs from instruments, avoiding unsupported claims?
What the Outcomes Present
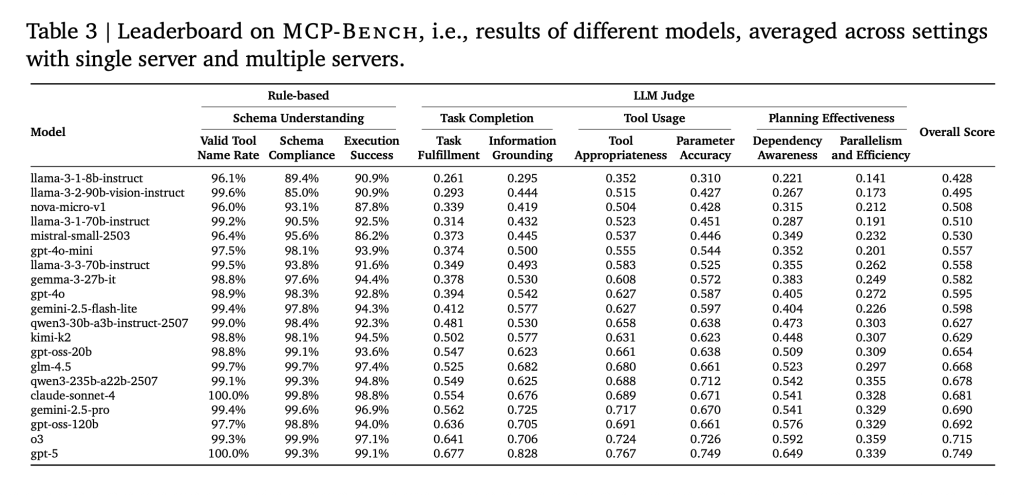
The researchers examined 20 state-of-the-art LLMs throughout 104 duties. The principle findings:
- Primary instrument use is strong: Most fashions may appropriately name instruments and deal with parameter schemas, even for complicated or domain-specific instruments.
- Planning remains to be arduous: Even the most effective fashions struggled with lengthy, multi-step workflows that required not simply choosing instruments, but in addition understanding when to maneuver to the subsequent step, which components can run in parallel, and how one can deal with sudden outcomes.
- Smaller fashions fall behind: As duties turned extra complicated, particularly these spanning a number of servers, smaller fashions have been extra more likely to make errors, repeat steps, or miss subtasks.
- Effectivity varies broadly: Some fashions wanted many extra instrument calls and rounds of interplay to realize the identical outcomes, suggesting inefficiencies in planning and execution.
- People are nonetheless wanted for nuance: Whereas the benchmark is automated, human checks guarantee duties are practical and solvable—a reminder that actually sturdy analysis nonetheless advantages from human experience.
Why This Analysis Issues?
MCP-Bench offers a sensible solution to assess how effectively AI brokers can act as “digital assistants” in real-world settings—conditions the place customers aren’t all the time exact and the suitable reply is dependent upon weaving collectively data from many sources. The benchmark exposes gaps in present LLM capabilities, particularly round complicated planning, cross-domain reasoning, and evidence-based synthesis—areas essential for deploying AI brokers in enterprise, analysis, and specialised fields.
Abstract
MCP-Bench is a severe, large-scale check for AI brokers utilizing actual instruments and actual duties, with no shortcuts or synthetic setups. It exhibits what present fashions do effectively and the place they nonetheless fall brief. For anybody constructing or evaluating AI assistants, these outcomes—and the benchmark itself—are more likely to be a helpful actuality examine.
Try the Paper and GitHub Page. Be at liberty to take a look at our GitHub Page for Tutorials, Codes and Notebooks. Additionally, be happy to comply with us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our Newsletter.

Michal Sutter is an information science skilled with a Grasp of Science in Knowledge Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and information engineering, Michal excels at reworking complicated datasets into actionable insights.