
On this tutorial, we stroll via Hugging Face Trackio step-by-step, exploring how we will observe experiments regionally, cleanly, and intuitively. We begin by putting in Trackio in Google Colab, getting ready a dataset, and establishing a number of coaching runs with completely different hyperparameters. Alongside the way in which, we log metrics, visualize confusion matrices as tables, and even import outcomes from a CSV file to exhibit the flexibleness of the instrument. By working all the pieces in a single pocket book, we acquire hands-on expertise with Trackio’s light-weight but highly effective dashboard, seeing our outcomes replace in actual time. Try the FULL CODES here.
!pip -q set up -U trackio scikit-learn pandas matplotlib
import os, time, math, json, random, pathlib, itertools, tempfile
from dataclasses import dataclass
import numpy as np
import pandas as pd
from sklearn.datasets import make_classification
from sklearn.linear_model import SGDClassifier
from sklearn.metrics import accuracy_score, log_loss, confusion_matrix
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import trackioWe start by putting in the required libraries, together with Trackio, scikit-learn, pandas, and matplotlib. We then import important Python modules and machine studying utilities in order that we will generate information, practice fashions, and observe experiments seamlessly. Try the FULL CODES here.
def make_dataset(n=12000, n_informative=18, n_classes=3, seed=42):
X, y = make_classification(
n_samples=n, n_features=32, n_informative=n_informative, n_redundant=0,
n_classes=n_classes, random_state=seed, class_sep=2.0
)
X_train, X_temp, y_train, y_temp = trn_tst_split(X, y, test_size=0.3, random_state=seed)
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=seed)
ss = StandardScaler().match(X_train)
return ss.remodel(X_train), y_train, ss.remodel(X_val), y_val, ss.remodel(X_test), y_test
def batches(X, y, bs, shuffle=True, seed=0):
idx = np.arange(len(X))
if shuffle:
rng = np.random.default_rng(seed)
rng.shuffle(idx)
for i in vary(0, len(X), bs):
j = idx[i:i+bs]
yield X[j], y[j]
def cm_table(y_true, y_pred):
cm = confusion_matrix(y_true, y_pred)
df = pd.DataFrame(cm, columns=[f"pred_{i}" for i in range(cm.shape[0])])
df.insert(0, "true", [f"true_{i}" for i in range(cm.shape[0])])
return dfWe create helper capabilities that permit us generate an artificial dataset, break up it into coaching, validation, and check units, batch the info for coaching, and construct confusion matrix tables. This fashion, we arrange all of the groundwork we want for clean mannequin coaching and analysis. Try the FULL CODES here.
@dataclass
class RunCfg:
lr: float = 0.05
l2: float = 1e-4
epochs: int = 8
batch_size: int = 256
seed: int = 0
undertaking: str = "trackio-demo"
def train_and_log(cfg: RunCfg, Xtr, ytr, Xva, yva):
run = trackio.init(
undertaking=cfg.undertaking,
title=f"sgd_lr{cfg.lr}_l2{cfg.l2}",
config={"lr": cfg.lr, "l2": cfg.l2, "epochs": cfg.epochs, "batch_size": cfg.batch_size, "seed": cfg.seed}
)
clf = SGDClassifier(loss="log_loss", penalty="l2", alpha=cfg.l2, learning_rate="fixed",
eta0=cfg.lr, random_state=cfg.seed)
n_classes = len(np.distinctive(ytr))
clf.partial_fit(Xtr[:cfg.batch_size], ytr[:cfg.batch_size], courses=np.arange(n_classes))
global_step = 0
for epoch in vary(cfg.epochs):
epoch_losses = []
for xb, yb in batches(Xtr, ytr, cfg.batch_size, shuffle=True, seed=cfg.seed + epoch):
clf.partial_fit(xb, yb)
probs = np.clip(clf.predict_proba(xb), 1e-9, 1 - 1e-9)
loss = log_loss(yb, probs, labels=np.arange(n_classes))
epoch_losses.append(loss)
global_step += 1
val_probs = np.clip(clf.predict_proba(Xva), 1e-9, 1 - 1e-9)
val_preds = np.argmax(val_probs, axis=1)
val_loss = log_loss(yva, val_probs, labels=np.arange(n_classes))
val_acc = accuracy_score(yva, val_preds)
train_loss = float(np.imply(epoch_losses))
trackio.log({
"epoch": epoch,
"train_loss": train_loss,
"val_loss": val_loss,
"val_accuracy": val_acc
})
if epoch in {cfg.epochs//2, cfg.epochs-1}:
df = cm_table(yva, val_preds)
tbl = trackio.Desk(dataframe=df)
trackio.log({f"val_confusion_epoch_{epoch}": tbl})
time.sleep(0.15)
trackio.end()
return val_accWe outline a configuration class to retailer our coaching settings and a train_and_log perform that runs an SGD classifier whereas logging metrics to Trackio. We observe losses, accuracy, and even confusion matrices throughout epochs, giving us each numeric and visible insights into mannequin efficiency in actual time. Try the FULL CODES here.
Xtr, ytr, Xva, yva, Xte, yte = make_dataset()
grid = record(itertools.product([0.01, 0.03, 0.1], [1e-5, 1e-4, 1e-3]))
outcomes = []
for lr, l2 in grid:
acc = train_and_log(RunCfg(lr=lr, l2=l2, seed=123), Xtr, ytr, Xva, yva)
outcomes.append({"lr": lr, "l2": l2, "val_acc": acc})
abstract = pd.DataFrame(outcomes).sort_values("val_acc", ascending=False).reset_index(drop=True)
greatest = abstract.iloc[0].to_dict()
run = trackio.init(undertaking="trackio-demo", title="abstract", config={"notice": "sweep outcomes"})
trackio.log({"best_val_acc": float(greatest["val_acc"]), "best_lr": float(greatest["lr"]), "best_l2": float(greatest["l2"])})
trackio.log({"sweep_table": trackio.Desk(dataframe=abstract)})
trackio.end()We run a small hyperparameter sweep over studying charge and L2, and we document every run’s validation accuracy. We then summarize the outcomes right into a desk, log the most effective configuration to Trackio, and end the abstract run. Try the FULL CODES here.
csv_path = "/content material/trackio_demo_metrics.csv"
df_csv = pd.DataFrame({
"step": np.arange(10),
"metric_x": np.linspace(1.0, 0.2, 10),
"metric_y": np.linspace(0.1, 0.9, 10),
})
df_csv.to_csv(csv_path, index=False)
trackio.import_csv(csv_path, undertaking="trackio-csv-import")
app = trackio.present(undertaking="trackio-demo")
# trackio.init(undertaking="myproj", space_id="username/trackio-demo-space")
We simulate a CSV file of metrics, import it into Trackio as a brand new undertaking, after which launch the dashboard for our primary undertaking. This lets us view each logged runs and exterior information aspect by aspect in Trackio’s interactive interface. Try the FULL CODES here.
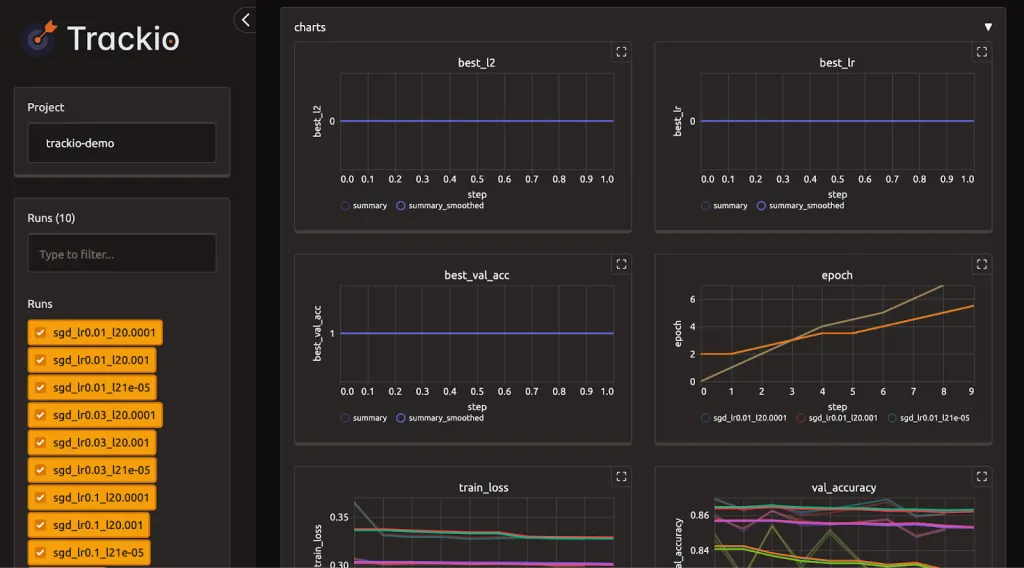
Trackio Dashboard Overview
In conclusion, we expertise how Trackio streamlines experiment monitoring with out the complexity of heavy infrastructure or API setups. We not solely log and examine runs but additionally seize structured outcomes, import exterior information, and launch an interactive dashboard instantly inside Colab. With this workflow, we see how Trackio empowers us to remain organized, monitor progress successfully, and make higher selections throughout experimentation. This tutorial provides us a robust basis to combine Trackio into our personal machine studying tasks seamlessly.
Try the FULL CODES here. Be happy to take a look at our GitHub Page for Tutorials, Codes and Notebooks. Additionally, be at liberty to observe us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.