
How can we construct AI techniques that continue to learn new info over time with out forgetting what they discovered earlier than or retraining from scratch? Google Researchers has launched Nested Studying, a machine studying strategy that treats a mannequin as a group of smaller nested optimization issues, as a substitute of a single community educated by one outer loop. The objective is to assault catastrophic forgetting and transfer massive fashions towards continuous studying, nearer to how organic brains handle reminiscence and adaptation over time.

What’s Nested Studying?
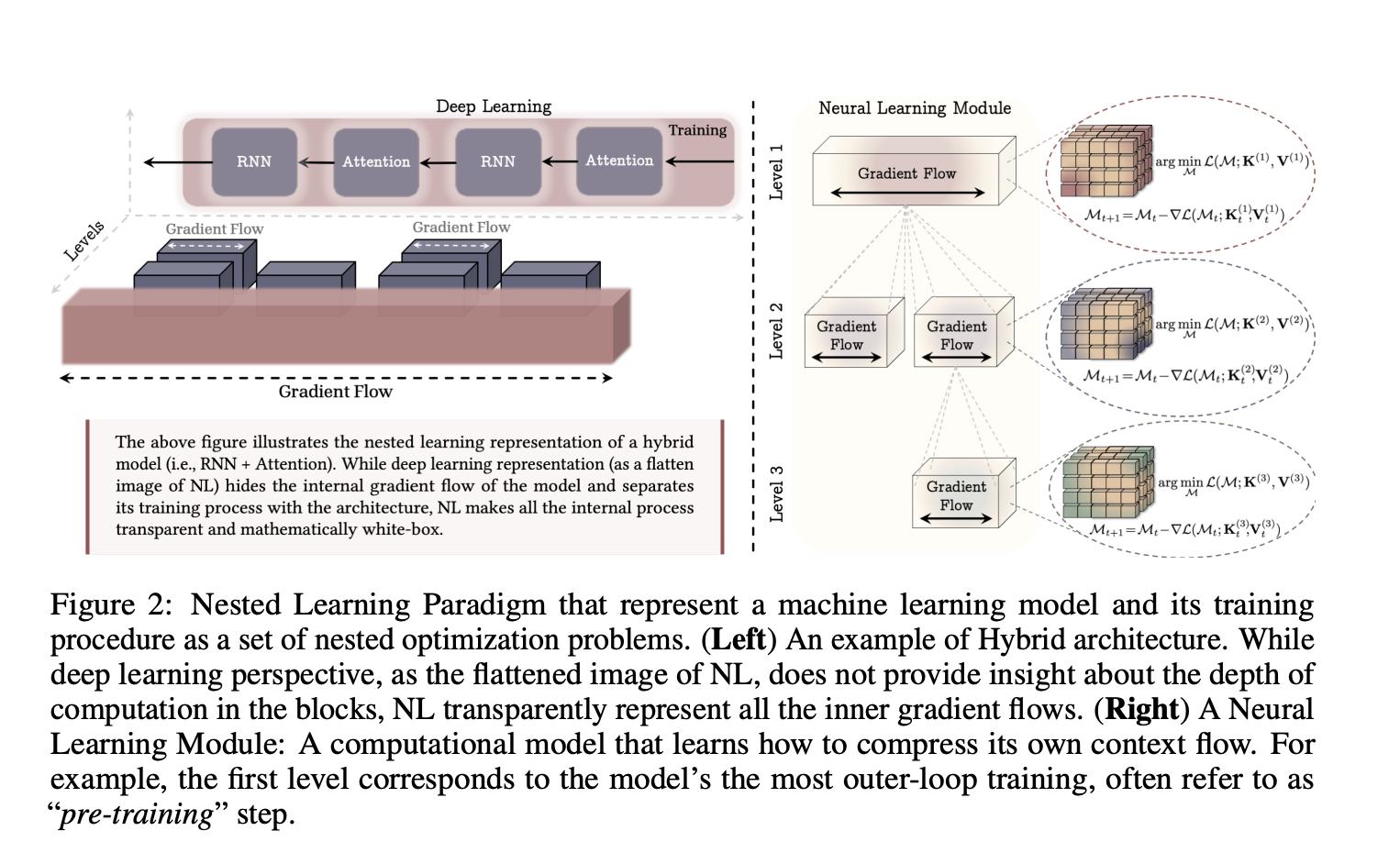
The analysis paper from Google ‘Nested Learning, The Illusion of Deep Learning Architectures’ fashions a fancy neural community as a set of coherent optimization issues, nested or working in parallel, which can be optimized collectively. Every inside drawback has its personal context stream, the sequence of inputs, gradients, or states that this part observes, and its personal replace frequency.
As an alternative of seeing coaching as a flat stack of layers plus one optimizer, Nested Studying imposes an ordering by replace frequency. Parameters that replace usually sit at interior ranges, whereas slowly up to date parameters kind outer ranges. This hierarchy defines a Neural Studying Module, the place each degree compresses its personal context stream into its parameters. The analysis group present that this view covers commonplace back-propagation on an MLP, linear consideration, and customary optimizers, all as situations of associative reminiscence.
On this framework, associative reminiscence is any operator that maps keys to values and is educated with an inside goal. The analysis group formalizes associative reminiscence after which reveals that back-propagation itself may be written as a one step gradient descent replace that learns a mapping from inputs to native shock indicators, the gradient of the loss with respect to the output.
Deep Optimizers as Associative Reminiscence
As soon as optimizers are handled as studying modules, Nested Studying suggests redesigning them with richer inside targets. Customary momentum may be written as a linear associative reminiscence over previous gradients, educated with a dot product similarity goal. This inside goal produces a Hebbian like replace rule that doesn’t mannequin dependencies between information samples.
The researcher group changed this similarity goal with an L2 regression loss over gradient options, which yields an replace rule that higher manages restricted reminiscence capability and higher memorizes gradient sequences. They then generalize the momentum reminiscence from a linear map to an MLP and outline Deep Momentum Gradient Descent, the place the momentum state is produced by a neural reminiscence and may cross by a non linear operate comparable to Newton Schulz. This attitude additionally recovers the Muon optimizer as a particular case.

Continuum Reminiscence System
In typical sequence fashions, consideration acts as working reminiscence over the present context window, whereas feedforward blocks retailer pre coaching information as long run reminiscence that’s not often up to date after coaching. The Nested Studying researchers prolong this binary view to a Continuum Reminiscence System, or CMS.
CMS is outlined as a series of MLP blocks, MLP(f₁) by MLP(fₖ), the place every block has its personal replace frequency and chunk measurement. For an enter sequence, the output is obtained by sequentially making use of these blocks. The parameters of every block are up to date solely each C^(ℓ) steps, so every block compresses a special time scale of context into its parameters. An ordinary Transformer with one feedforward block is recovered because the particular case with ok equal to 1.
This building turns long run reminiscence right into a spectrum of ranges throughout frequency, as a substitute of a single static feedforward layer. The analysis connects this on to multi time scale synaptic and system consolidation processes within the mind, the place completely different components of the system study at completely different charges whereas sharing a typical structure.
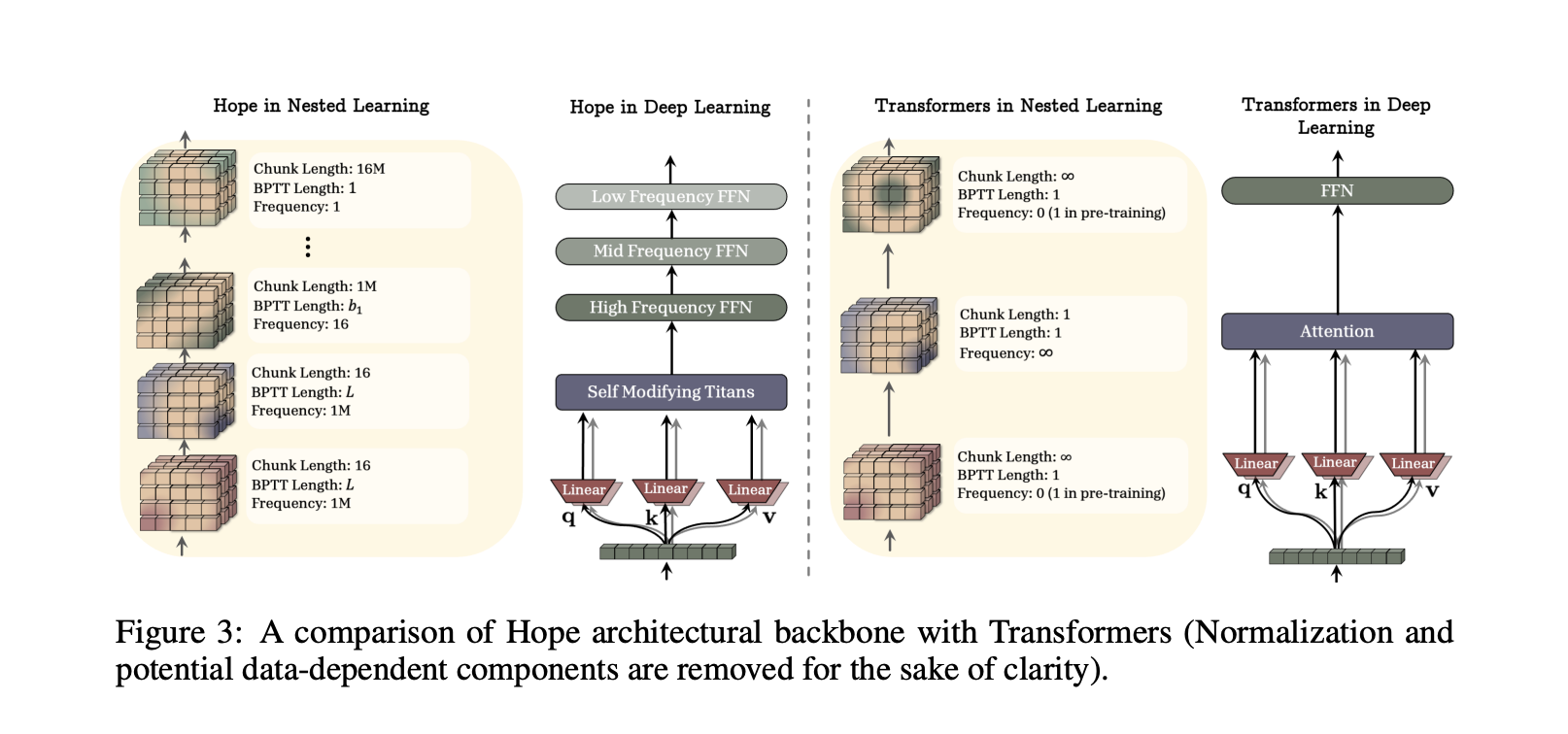
HOPE, A Self Modifying Structure Constructed On Titans
To indicate that Nested Studying is sensible, the analysis group designed HOPE, a self referential sequence mannequin that applies the paradigm to a recurrent structure. HOPE is constructed as a variant of Titans, a long run reminiscence structure the place a neural reminiscence module learns to memorize stunning occasions at take a look at time and helps consideration attend to gone tokens.
Titans has solely 2 ranges of parameter replace, which yields first order in context studying. HOPE extends Titans in 2 methods. First, it’s self modifying, it will probably optimize its personal reminiscence by a self referential course of and may in precept help unbounded ranges of in context studying. Second, it integrates Continuum Reminiscence System blocks in order that reminiscence updates happen at a number of frequencies and scale to longer context home windows.
Understanding the Outcomes
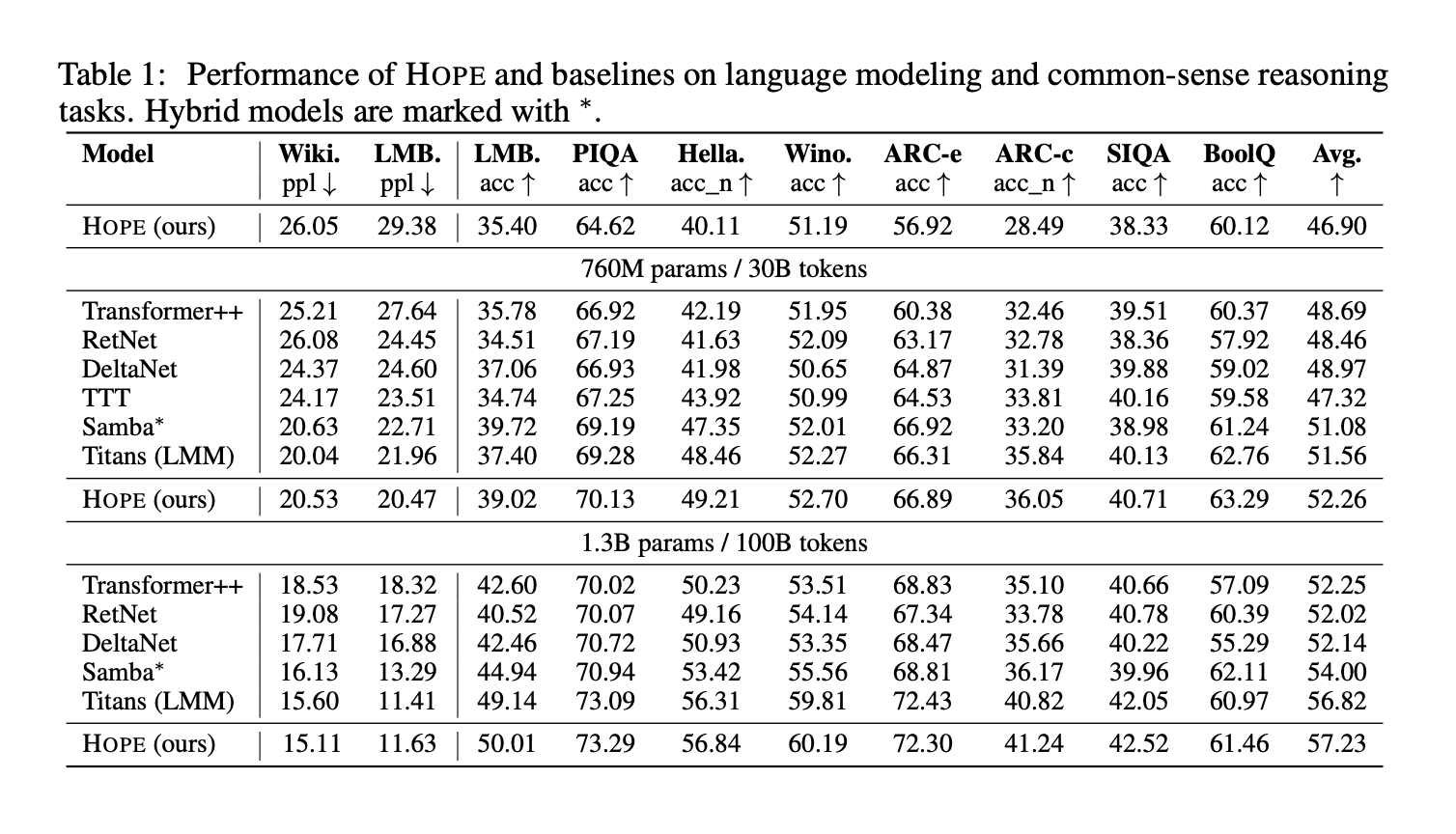
The analysis group evaluates HOPE and baselines on language modeling and customary sense reasoning duties at 3 parameter scales, 340M, 760M, and 1.3B parameters. Benchmarks embody Wiki and LMB perplexity for language modeling and PIQA, HellaSwag, WinoGrande, ARC Straightforward, ARC Problem, Social IQa, and BoolQ accuracy for reasoning. The beneath given Desk 1 reviews outcomes for HOPE, Transformer++, RetNet, Gated DeltaNet, TTT, Samba, and Titans.
Key Takeaways
- Nested Studying treats a mannequin as a number of nested optimization issues with completely different replace frequencies, which straight targets catastrophic forgetting in continuous studying.
- The framework reinterprets backpropagation, consideration, and optimizers as associative reminiscence modules that compress their very own context stream, giving a unified view of structure and optimization.
- Deep optimizers in Nested Studying change easy dot product similarity with richer targets comparable to L2 regression and use neural recollections, which results in extra expressive and context conscious replace guidelines.
- The Continuum Reminiscence System fashions reminiscence as a spectrum of MLP blocks that replace at completely different charges, creating brief, medium, and lengthy vary reminiscence moderately than one static feedforward layer.
- The HOPE structure, a self modifying variant of Titans constructed utilizing Nested Studying rules, reveals improved language modeling, lengthy context reasoning, and continuous studying efficiency in comparison with robust Transformer and recurrent baselines.
Nested Studying is a helpful reframing of deep networks as Neural Studying Modules that combine structure and optimization into one system. The introduction of Deep Momentum Gradient Descent, Continuum Reminiscence System, and the HOPE structure provides a concrete path to richer associative reminiscence and higher continuous studying. General, this work turns continuous studying from an afterthought right into a main design axis.
Take a look at the Paper and Technical Details. Be at liberty to take a look at our GitHub Page for Tutorials, Codes and Notebooks. Additionally, be happy to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.