
A staff of researchers from Meta Actuality Labs and Carnegie Mellon College has launched MapAnything, an end-to-end transformer structure that straight regresses factored metric 3D scene geometry from photographs and non-compulsory sensor inputs. Launched below Apache 2.0 with full coaching and benchmarking code, MapAnything advances past specialist pipelines by supporting over 12 distinct 3D imaginative and prescient duties in a single feed-forward move.

Why a Common Mannequin for 3D Reconstruction?
Picture-based 3D reconstruction has traditionally relied on fragmented pipelines: characteristic detection, two-view pose estimation, bundle adjustment, multi-view stereo, or monocular depth inference. Whereas efficient, these modular options require task-specific tuning, optimization, and heavy post-processing.
Latest transformer-based feed-forward fashions comparable to DUSt3R, MASt3R, and VGGT simplified components of this pipeline however remained restricted: mounted numbers of views, inflexible digital camera assumptions, or reliance on coupled representations that wanted costly optimization.
MapAnything overcomes these constraints by:
- Accepting as much as 2,000 enter photographs in a single inference run.
- Flexibly utilizing auxiliary knowledge comparable to digital camera intrinsics, poses, and depth maps.
- Producing direct metric 3D reconstructions with out bundle adjustment.
The mannequin’s factored scene illustration—composed of ray maps, depth, poses, and a worldwide scale issue—supplies modularity and generality unmatched by prior approaches.
Structure and Illustration
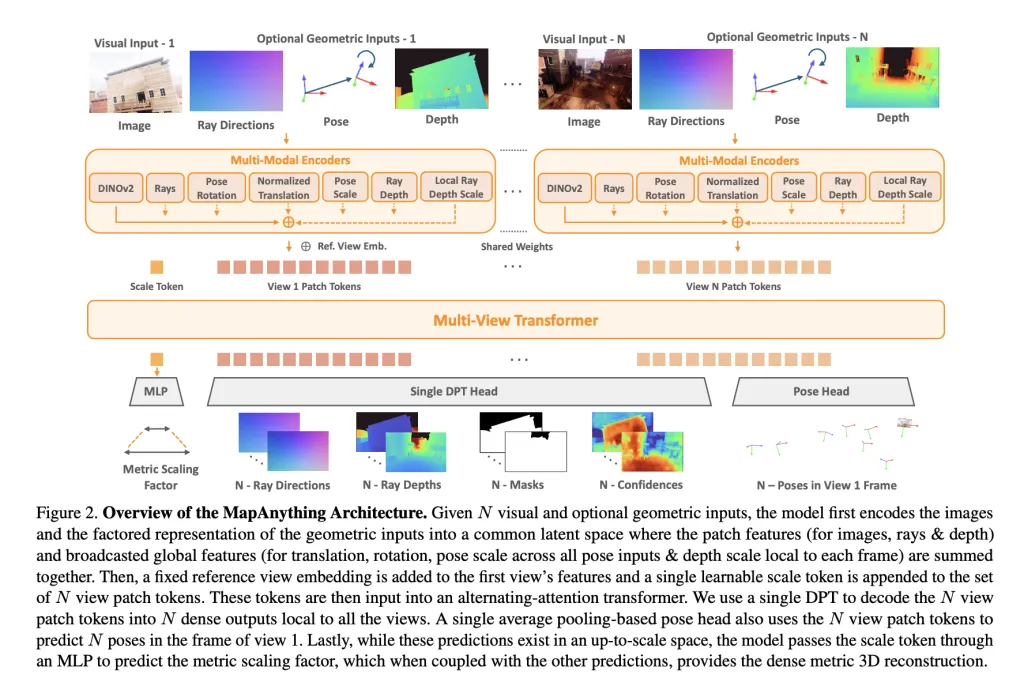
At its core, MapAnything employs a multi-view alternating-attention transformer. Every enter picture is encoded with DINOv2 ViT-L options, whereas non-compulsory inputs (rays, depth, poses) are encoded into the identical latent house by way of shallow CNNs or MLPs. A learnable scale token permits metric normalization throughout views.
The community outputs a factored illustration:
- Per-view ray instructions (digital camera calibration).
- Depth alongside rays, predicted up-to-scale.
- Digicam poses relative to a reference view.
- A single metric scale issue changing native reconstructions right into a globally constant body.
This specific factorization avoids redundancy, permitting the identical mannequin to deal with monocular depth estimation, multi-view stereo, structure-from-motion (SfM), or depth completion with out specialised heads.
Coaching Technique
MapAnything was skilled throughout 13 various datasets spanning indoor, outside, and artificial domains, together with BlendedMVS, Mapillary Planet-Scale Depth, ScanNet++, and TartanAirV2. Two variants are launched:
- Apache 2.0 licensed mannequin skilled on six datasets.
- CC BY-NC mannequin skilled on all 13 datasets for stronger efficiency.
Key coaching methods embrace:
- Probabilistic enter dropout: Throughout coaching, geometric inputs (rays, depth, pose) are supplied with various possibilities, enabling robustness throughout heterogeneous configurations.
- Covisibility-based sampling: Ensures enter views have significant overlap, supporting reconstruction as much as 100+ views.
- Factored losses in log-space: Depth, scale, and pose are optimized utilizing scale-invariant and strong regression losses to enhance stability.
Coaching was carried out on 64 H200 GPUs with combined precision, gradient checkpointing, and curriculum scheduling, scaling from 4 to 24 enter views.
Benchmarking Outcomes
Multi-View Dense Reconstruction
On ETH3D, ScanNet++ v2, and TartanAirV2-WB, MapAnything achieves state-of-the-art (SoTA) efficiency throughout pointmaps, depth, pose, and ray estimation. It surpasses baselines like VGGT and Pow3R even when restricted to photographs solely, and improves additional with calibration or pose priors.
For instance:
- Pointmap relative error (rel) improves to 0.16 with solely photographs, in comparison with 0.20 for VGGT.
- With photographs + intrinsics + poses + depth, the error drops to 0.01, whereas attaining >90% inlier ratios.
Two-View Reconstruction
In opposition to DUSt3R, MASt3R, and Pow3R, MapAnything persistently outperforms throughout scale, depth, and pose accuracy. Notably, with further priors, it achieves >92% inlier ratios on two-view duties, considerably past prior feed-forward fashions.
Single-View Calibration
Regardless of not being skilled particularly for single-image calibration, MapAnything achieves an common angular error of 1.18°, outperforming AnyCalib (2.01°) and MoGe-2 (1.95°).
Depth Estimation
On the Sturdy-MVD benchmark:
- MapAnything units new SoTA for multi-view metric depth estimation.
- With auxiliary inputs, its error charges rival or surpass specialised depth fashions comparable to MVSA and Metric3D v2.
Total, benchmarks verify 2× enchancment over prior SoTA strategies in lots of duties, validating the advantages of unified coaching.
Key Contributions
The analysis staff spotlight 4 main contributions:
- Unified Feed-Ahead Mannequin able to dealing with greater than 12 downside settings, from monocular depth to SfM and stereo.
- Factored Scene Illustration enabling specific separation of rays, depth, pose, and metric scale.
- State-of-the-Artwork Efficiency throughout various benchmarks with fewer redundancies and better scalability.
- Open-Supply Launch together with knowledge processing, coaching scripts, benchmarks, and pretrained weights below Apache 2.0.
Conclusion
MapAnything establishes a brand new benchmark in 3D imaginative and prescient by unifying a number of reconstruction duties—SfM, stereo, depth estimation, and calibration—below a single transformer mannequin with a factored scene illustration. It not solely outperforms specialist strategies throughout benchmarks but additionally adapts seamlessly to heterogeneous inputs, together with intrinsics, poses, and depth. With open-source code, pretrained fashions, and assist for over 12 duties, MapAnything lays the groundwork for a really general-purpose 3D reconstruction spine.
Try the Paper, Codes and Project Page. Be happy to take a look at our GitHub Page for Tutorials, Codes and Notebooks. Additionally, be happy to comply with us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our Newsletter.

Michal Sutter is an information science skilled with a Grasp of Science in Knowledge Science from the College of Padova. With a stable basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at reworking advanced datasets into actionable insights.