
Neuroscience has lengthy been a subject of divide and conquer. Researchers usually map particular cognitive features to remoted mind areas—like movement to space V5 or faces to the fusiform gyrus—utilizing fashions tailor-made to slim experimental paradigms. Whereas this has supplied deep insights, the ensuing panorama is fragmented, missing a unified framework to elucidate how the human mind integrates multisensory info.
Meta’s FAIR staff has launched TRIBE v2, a tri-modal basis mannequin designed to bridge this hole. By aligning the latent representations of state-of-the-art AI architectures with human mind exercise, TRIBE v2 predicts high-resolution fMRI responses throughout numerous naturalistic and experimental circumstances.

The Structure: Multi-modal Integration
TRIBE v2 doesn’t be taught to ‘see’ or ‘hear’ from scratch. As an alternative, it leverages the representational alignment between deep neural networks and the primate mind. The structure consists of three frozen basis fashions serving as characteristic extractors, a temporal transformer, and a subject-specific prediction block.
The mannequin processes stimuli via three specialised encoders:
- Textual content: Contextualized embeddings are extracted from LLaMA 3.2-3B. For each phrase, the mannequin prepends the previous 1,024 phrases to offer temporal context, which is then mapped to a 2 Hz grid.
- Video: The mannequin makes use of V-JEPA2-Large to course of 64-frame segments spanning the previous 4 seconds for every time-bin.
- Audio: Sound is processed via Wav2Vec-BERT 2.0, with representations resampled to 2 Hz to match the stimulus frequency .
2. Temporal Aggregation
The ensuing embeddings are compressed right into a shared dimension and concatenated to kind a multi-modal time sequence with a mannequin dimension of . This sequence is fed right into a Transformer encoder (8 layers, 8 consideration heads) that exchanges info throughout a 100-second window.
3. Topic-Particular Prediction
To foretell mind exercise, the Transformer outputs are decimated to the 1 Hz fMRI frequency and handed via a Topic Block. This block initiatives the latent representations to twenty,484 cortical vertices and eight,802 subcortical voxels.
Knowledge and Scaling Legal guidelines
A major hurdle in mind encoding is knowledge shortage. TRIBE v2 addresses this by using ‘deep’ datasets for coaching—the place just a few topics are recorded for a lot of hours—and ‘large’ datasets for analysis.
- Coaching: The mannequin was educated on 451.6 hours of fMRI knowledge from 25 topics throughout 4 naturalistic research (films, podcasts, and silent movies).
- Analysis: It was evaluated throughout a broader assortment totaling 1,117.7 hours from 720 topics.
The analysis staff noticed a log-linear enhance in encoding accuracy because the coaching knowledge quantity elevated, with no proof of a plateau. This means that as neuroimaging repositories increase, the predictive energy of fashions like TRIBE v2 will proceed to scale.
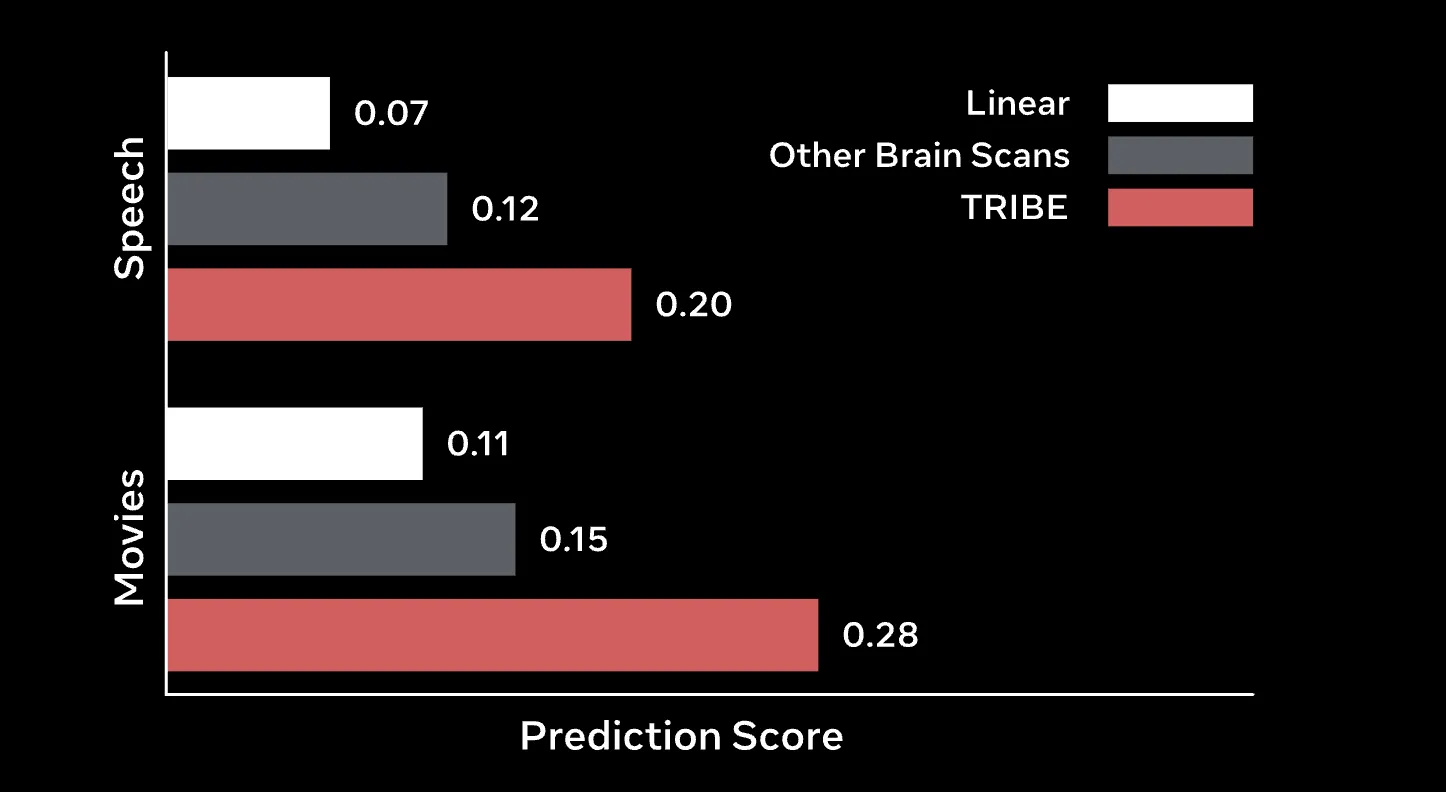
Outcomes: Beating the Baselines
TRIBE v2 considerably outperforms conventional Finite Impulse Response (FIR) fashions, the long-standing gold normal for voxel-wise encoding.
Zero-Shot and Group Efficiency
One of many mannequin’s most putting capabilities is zero-shot generalization to new topics. Utilizing an ‘unseen topic’ layer, TRIBE v2 can predict the group-averaged response of a brand new cohort extra precisely than the precise recording of many particular person topics inside that cohort. Within the high-resolution Human Connectome Challenge (HCP) 7T dataset, TRIBE v2 achieved a bunch correlation close to 0.4, a two-fold enchancment over the median topic’s group-predictivity.
Fantastic-Tuning
When given a small quantity of information (at most one hour) for a brand new participant, fine-tuning TRIBE v2 for only one epoch results in a two- to four-fold enchancment over linear fashions educated from scratch.
In-Silico Experimentation
The analysis staff argue that TRIBE v2 may very well be helpful for piloting or pre-screening neuroimaging research. By operating digital experiments on the Particular person Mind Charting (IBC) dataset, the mannequin recovered traditional practical landmarks:
- Imaginative and prescient: It precisely localized the fusiform face space (FFA) and parahippocampal place space (PPA).
- Language: It efficiently recovered the temporo-parietal junction (TPJ) for emotional processing and Broca’s space for syntax.
Moreover, making use of Unbiased Element Evaluation (ICA) to the mannequin’s closing layer revealed that TRIBE v2 naturally learns 5 well-known practical networks: main auditory, language, movement, default mode, and visible.
Key Takeaway
- A Powerhouse Tri-modal Structure: TRIBE v2 is a basis mannequin that integrates video, audio, and language by leveraging state-of-the-art encoders like LLaMA 3.2 for textual content, V-JEPA2 for video, and Wav2Vec-BERT for audio.
- Log-Linear Scaling Legal guidelines: Very similar to the Massive Language Fashions we use each day, TRIBE v2 follows a log-linear scaling regulation; its skill to precisely predict mind exercise will increase steadily as it’s fed extra fMRI knowledge, with no efficiency plateau presently in sight.
- Superior Zero-Shot Generalization: The mannequin can predict the mind responses of unseen topics in new experimental circumstances with none extra coaching. Remarkably, its zero-shot predictions are sometimes extra correct at estimating group-averaged mind responses than the recordings of particular person human topics themselves.
- The Daybreak of In-Silico Neuroscience: TRIBE v2 allows ‘in-silico’ experimentation, permitting researchers to run digital neuroscientific exams on a pc. It efficiently replicated a long time of empirical analysis by figuring out specialised areas just like the fusiform face space (FFA) and Broca’s space purely via digital simulation.
- Emergent Organic Interpretability: Though it’s a deep studying ‘black field,’ the mannequin’s inner representations naturally organized themselves into 5 well-known practical networks: main auditory, language, movement, default mode, and visible.
Take a look at the Code, Weights and Demo. Additionally, be happy to comply with us on Twitter and don’t neglect to hitch our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.

Michal Sutter is an information science skilled with a Grasp of Science in Knowledge Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at reworking complicated datasets into actionable insights.