
The scaling of Giant Language Fashions (LLMs) is more and more constrained by reminiscence communication overhead between Excessive-Bandwidth Reminiscence (HBM) and SRAM. Particularly, the Key-Worth (KV) cache dimension scales with each mannequin dimensions and context size, creating a major bottleneck for long-context inference. Google analysis staff has proposed TurboQuant, a data-oblivious quantization framework designed to attain near-optimal distortion charges for high-dimensional Euclidean vectors whereas addressing each mean-squared error (MSE) and inside product distortion.
Addressing the Reminiscence Wall with Knowledge-Oblivious VQ
Vector quantization (VQ) in Euclidean area is a foundational drawback rooted in Shannon’s supply coding idea. Conventional VQ algorithms, comparable to Product Quantization (PQ), usually require in depth offline preprocessing and data-dependent codebook coaching, making them ill-suited for the dynamic necessities of real-time AI workloads like KV cache administration.
TurboQuant is a ‘data-oblivious’ algorithm and it doesn’t require dataset-specific tuning or calibrations. It’s designed to be extremely appropriate with fashionable accelerators like GPUs by leveraging vectorized operations reasonably than sluggish, non-parallelizable binary searches.
The Geometric Mechanics of TurboQuant
The core mechanism of TurboQuant includes making use of a random rotation  Π E Rdxd to the enter vectors. This rotation induces a concentrated Beta distribution on every coordinate, whatever the authentic enter knowledge. In excessive dimensions, these coordinates grow to be almost impartial and identically distributed (i.i.d.).
Π E Rdxd to the enter vectors. This rotation induces a concentrated Beta distribution on every coordinate, whatever the authentic enter knowledge. In excessive dimensions, these coordinates grow to be almost impartial and identically distributed (i.i.d.).
This near-independence simplifies the quantization design, permitting TurboQuant to unravel a steady 1D k-means / Max-Lloyd scalar quantization drawback per coordinate. The optimum scalar quantizer for a given bit-width b is discovered by minimizing the next MSE price operate:
$$mathcal{C}(f_{X},b):=min_{-1le c_{1}le c_{2}le…le c_{2^{b}}le1}sum_{i=1}^{2^{b}}int_{frac{c_{i-1}+c_{i}}{2}}^{frac{c_{i}+c_{i+1}}{2}}|x-c_{i}|^{2}cdot f_{X}(x)dx$$
By fixing this optimization as soon as for related bit-widths and storing the ensuing codebooks, TurboQuant can effectively quantize vectors throughout on-line inference.
Eliminating Inside Product Bias
A major problem in quantization is that maps optimized strictly for MSE usually introduce bias when estimating inside merchandise, that are the elemental operations in transformer consideration mechanisms. For instance, a 1-bit MSE-optimal quantizer in excessive dimensions can exhibit a multiplicative bias of two/π.
To right this, Google Analysis developed TURBOQUANTprod, a two-stage method:
- MSE Stage: It applies a TURBOQUANTmse quantizer utilizing a bit-width of b-1 to reduce the L2 norm of the residual vector.
- Unbiased Stage: It applies a 1-bit Quantized Johnson-Lindenstrauss (QJL) remodel to the residual vector.
This mixture leads to an general bit-width of b whereas offering a provably unbiased estimator for inside merchandise:
(mathbb{E}_{Q}[langle y,Q^{-1}(Q(x))rangle ]=langle y,xrangle )
Theoretical and Empirical Efficiency
The analysis staff established information-theoretic decrease bounds utilizing Shannon’s Decrease Certain (SLB) and Yao’s minimax precept. TurboQuant’s MSE distortion is provably inside a small fixed issue (≈ 2.7) of absolutely the theoretical restrict throughout all bit-widths. At a bit-width of b=1, it’s only an element of roughly 1.45 away from the optimum.
| Bit-width (b) | TURBOQUANTmse Distortion | Data-Theoretic Decrease Certain |
| 1 | 0.36 | 0.25 |
| 2 | 0.117 | 0.0625 |
| 3 | 0.03 | 0.0156 |
| 4 | 0.009 | 0.0039 |
In end-to-end LLM era benchmarks utilizing Llama-3.1-8B-Instruct and Ministral-7B-Instruct, TurboQuant demonstrated prime quality retention. Underneath a 4x compression ratio, the mannequin maintained 100% retrieval accuracy on the Needle-In-A-Haystack benchmark. Within the Needle-In-A-Haystack benchmark, TurboQuant matched full-precision efficiency as much as 104k tokens below 4× compression.
For non-integer bit-widths, the system employs an outlier remedy technique, allocating increased precision (e.g., 3 bits) to particular outlier channels and decrease precision (e.g., 2 bits) to non-outliers, leading to efficient bit-rates like 2.5 or 3.5 bits per channel.
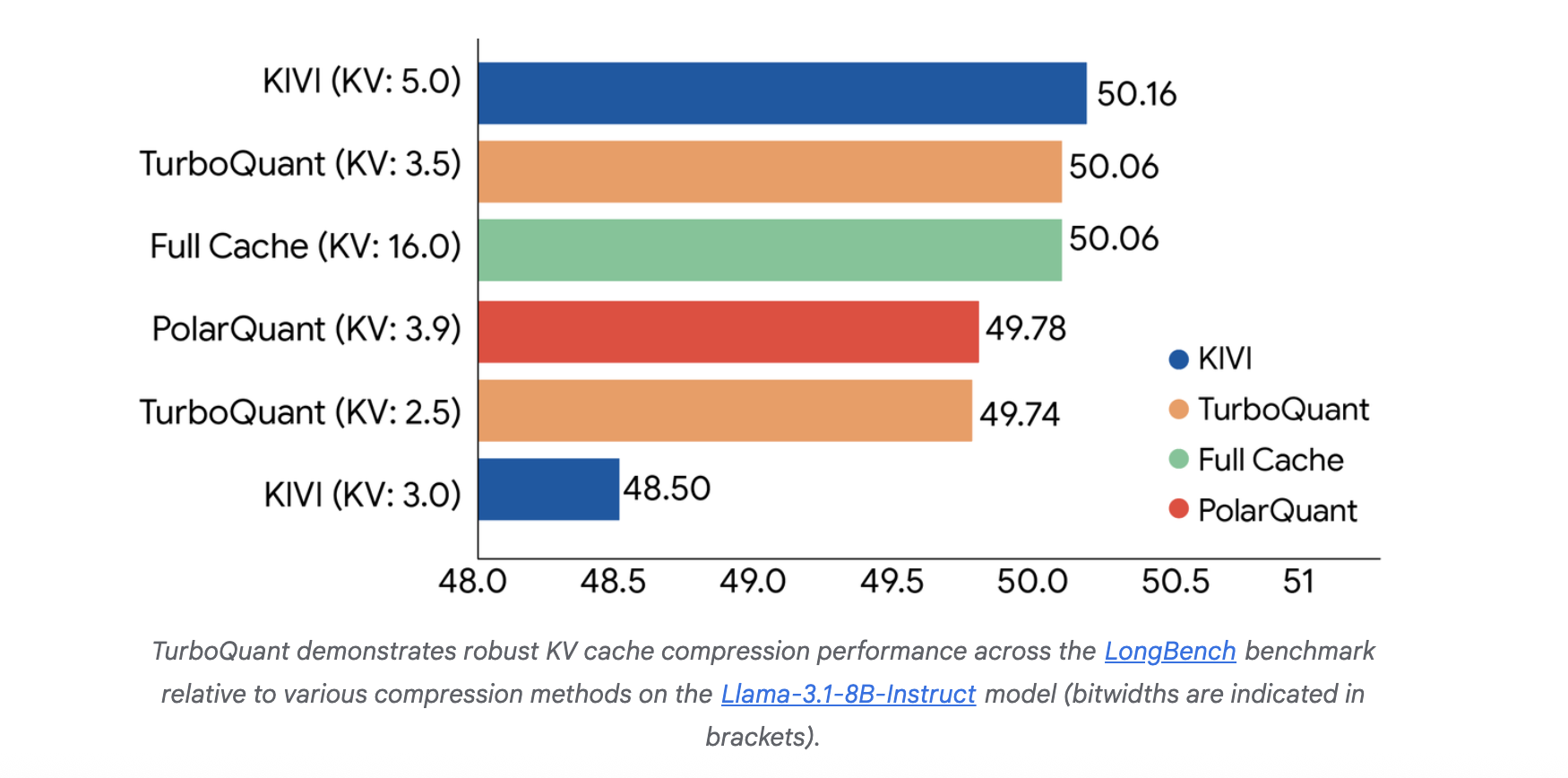
Pace and Indexing Effectivity
In nearest neighbor search duties, TurboQuant outperformed normal Product Quantization (PQ) and RabitQ in recall whereas lowering indexing time to just about zero. As a result of TurboQuant is data-oblivious, it eliminates the necessity for the time-consuming k-means coaching part required by PQ, which might take a whole bunch of seconds for big datasets.
| Strategy | d=200 Indexing | d=1536 Indexing | d=3072 Indexing |
| Product Quantization | 37.04s | 239.75s | 494.42s |
| TurboQuant | 0.0007s | 0.0013s | 0.0021s |
TurboQuant represents a mathematically grounded shift towards environment friendly, hardware-compatible vector quantization that bridges the hole between theoretical distortion limits and sensible AI deployment.
Key Takeaways
- Zero Preprocessing Required: Not like normal Product Quantization (PQ), TurboQuant is data-oblivious and it really works immediately while not having time-consuming k-means coaching in your particular dataset.
- Close to-Theoretical Perfection: It achieves near-optimal distortion charges, remaining inside a small fixed issue of roughly 2.7 of the information-theoretic decrease certain established by Shannon.
- Unbiased Inside Merchandise: Through the use of a two-stage method—making use of MSE-optimal quantization adopted by a 1-bit QJL remodel on the residual—it offers unbiased inside product estimates, which is important for sustaining the accuracy of transformer consideration mechanisms.
- Large Reminiscence Financial savings: In LLM deployment, it compresses the KV cache by over 5x. It achieves absolute high quality neutrality at 3.5 bits per channel and maintains 100% recall in ‘needle-in-a-haystack’ exams as much as 104k tokens.
- Instantaneous Indexing for Search: For vector databases, TurboQuant reduces indexing time to just about zero (e.g., 0.0013s for 1536-dimensional vectors) whereas persistently outperforming conventional PQ in search recall.
Take a look at the Paper and Technical details. Additionally, be happy to observe us on Twitter and don’t overlook to affix our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.

