Generative AI’s current trajectory relies heavily on Latent Diffusion Models (LDMs) to manage the computational cost of high-resolution synthesis. By compressing data into a lower-dimensional latent space, models can scale effectively. However, a fundamental trade-off persists: lower information density makes latents easier to learn but sacrifices reconstruction quality, while higher density enables near-perfect reconstruction but demands greater modeling capacity.
Google DeepMind researchers have introduced Unified Latents (UL), a framework designed to navigate this trade-off systematically. The framework jointly regularizes latent representations with a diffusion prior and decodes them via a diffusion model.
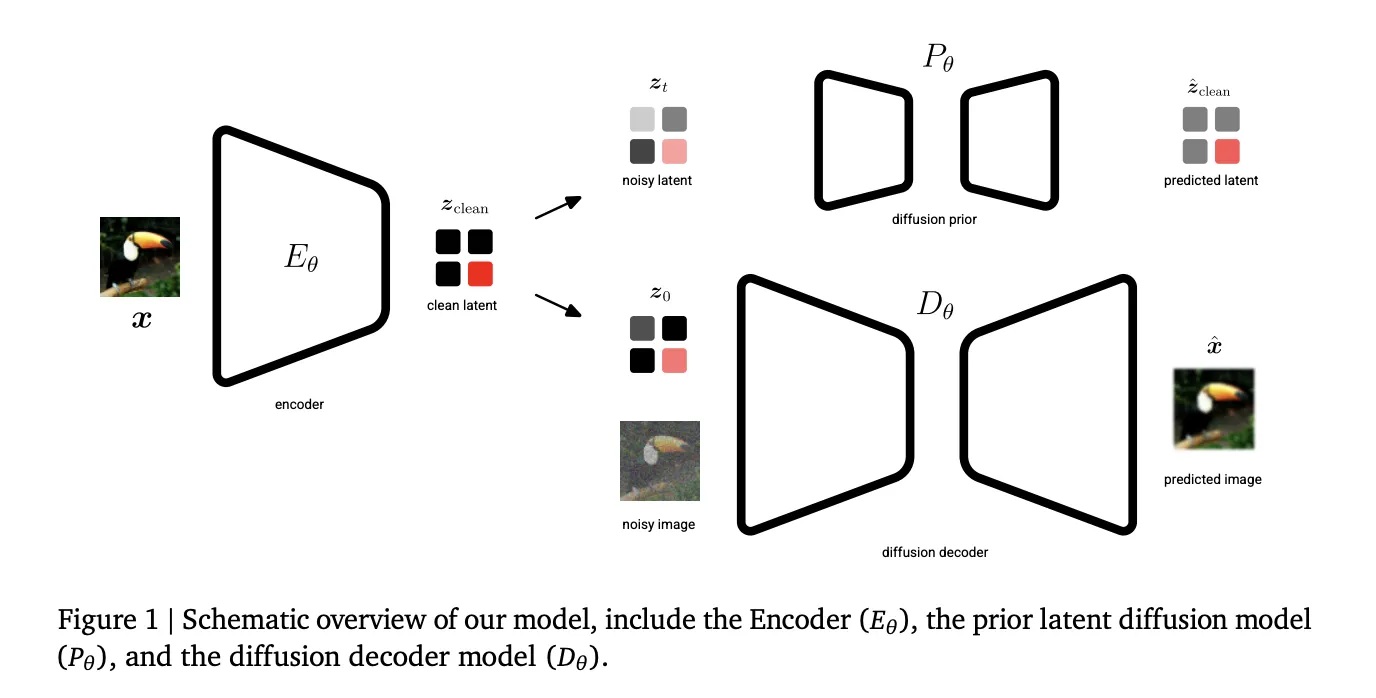
The Architecture: Three Pillars of Unified Latents
The Unified Latents (UL) framework rests on three specific technical components:
- Fixed Gaussian Noise Encoding: Unlike standard Variational Autoencoders (VAEs) that learn an encoder distribution, UL uses a deterministic encoder E𝝷 that predicts a single latent zclean. This latent is then forward-noised to a final log signal-to-noise ratio (log-SNR) of λ(0)=5.
- Prior-Alignment: The prior diffusion model is aligned with this minimum noise level. This alignment allows the Kullback-Leibler (KL) term in the Evidence Lower Bound (ELBO) to reduce to a simple weighted Mean Squared Error (MSE) over noise levels.
- Reweighted Decoder ELBO: The decoder utilizes a sigmoid-weighted loss, which provides an interpretable bound on the latent bitrate while allowing the model to prioritize different noise levels.
The Two-Stage Training Process
The UL framework is implemented in two distinct stages to optimize both latent learning and generation quality.
Stage 1: Joint Latent Learning
In the first stage, the encoder, diffusion prior (P𝝷), and diffusion decoder (D𝝷) are trained jointly. The objective is to learn latents that are simultaneously encoded, regularized, and modeled. The encoder’s output noise is linked directly to the prior’s minimum noise level, providing a tight upper bound on the latent bitrate.
Stage 2: Base Model Scaling
The research team found that a prior trained solely on an ELBO loss in Stage 1 does not produce optimal samples because it weights low-frequency and high-frequency content equally. Consequently, in Stage 2, the encoder and decoder are frozen. A new ‘base model’ is then trained on the latents using a sigmoid weighting, which significantly improves performance. This stage allows for larger model sizes and batch sizes.
Technical Performance and SOTA Benchmarks
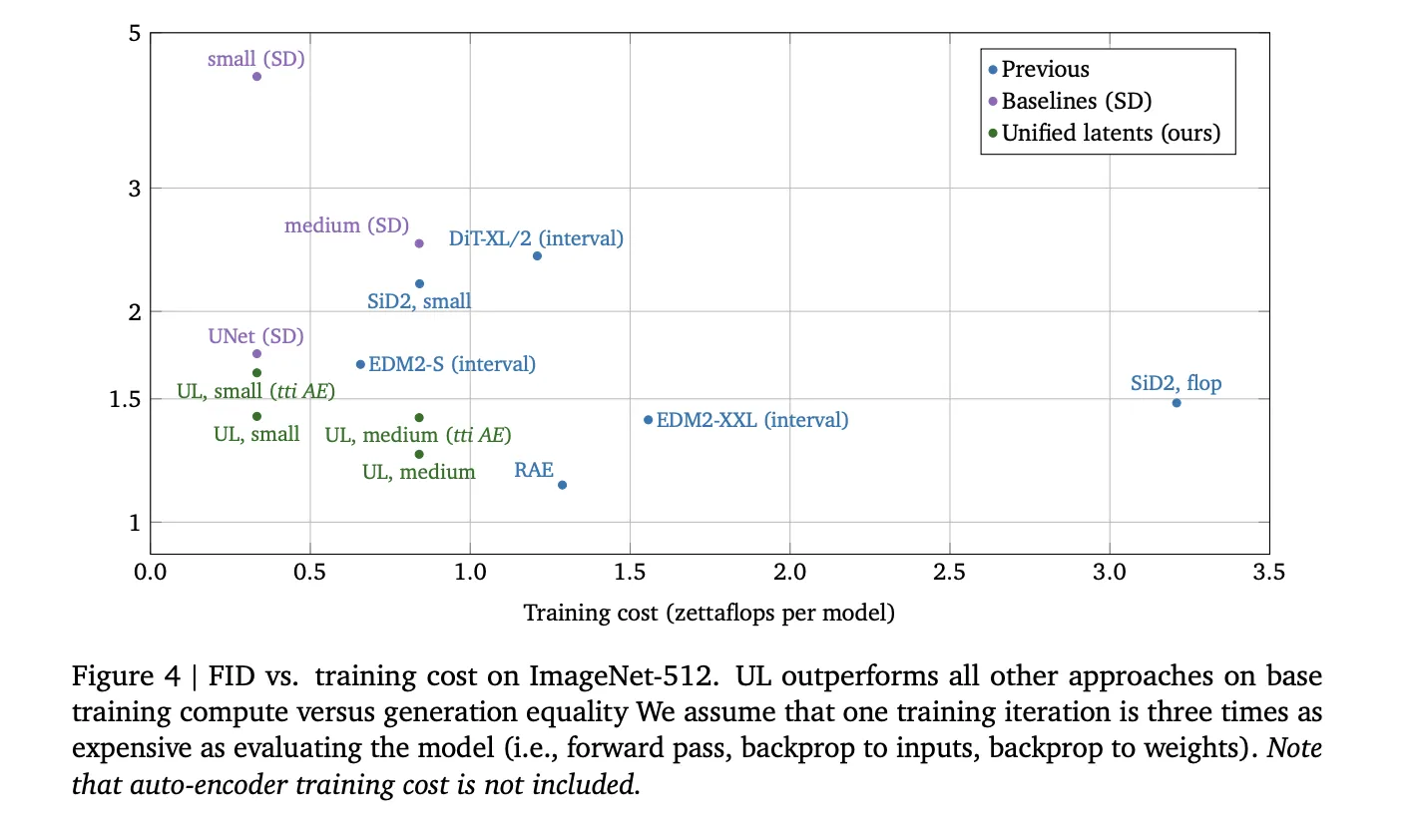
Unified Latents demonstrate high efficiency in the relationship between training compute (FLOPs) and generation quality.
| Metric | Dataset | Result | Significance |
| FID | ImageNet-512 | 1.4 | Outperforms models trained on Stable Diffusion latents for a given compute budget. |
| FVD | Kinetics-600 | 1.3 | Sets a new State-of-the-Art (SOTA) for video generation. |
| PSNR | ImageNet-512 | Up to 30.1 | Maintains high reconstruction fidelity even at higher compression levels. |
On ImageNet-512, UL outperformed previous approaches, including DiT and EDM2 variants, in terms of training cost versus generation FID. In video tasks using Kinetics-600, a small UL model achieved a 1.7 FVD, while the medium variant reached the SOTA 1.3 FVD.
Key Takeaways
- Integrated Diffusion Framework: UL is a framework that jointly optimizes an encoder, a diffusion prior, and a diffusion decoder, ensuring that latent representations are simultaneously encoded, regularized, and modeled for high-efficiency generation.
- Fixed-Noise Information Bound: By using a deterministic encoder that adds a fixed amount of Gaussian noise (specifically at a log-SNR of λ(0)=5) and linking it to the prior’s minimum noise level, the model provides a tight, interpretable upper bound on the latent bitrate.
- Two-Stage Training Strategy: The process involves an initial joint training stage for the autoencoder and prior, followed by a second stage where the encoder and decoder are frozen and a larger ‘base model’ is trained on the latents to maximize sample quality.
- State-of-the-Art Performance: The framework established a new state-of-the-art (SOTA) Fréchet Video Distance (FVD) of 1.3 on Kinetics-600 and achieved a competitive Fréchet Inception Distance (FID) of 1.4 on ImageNet-512 while requiring fewer training FLOPs than standard latent diffusion baselines.
Check out the Paper. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
