
Alibaba Tongyi Lab analysis crew launched ‘Zvec’, an open supply, in-process vector database that targets edge and on-device retrieval workloads. It’s positioned as ‘the SQLite of vector databases’ as a result of it runs as a library inside your software and doesn’t require any exterior service or daemon. It’s designed for retrieval augmented technology (RAG), semantic search, and agent workloads that should run regionally on laptops, cellular gadgets, or different constrained {hardware}/edge gadgets
The core concept is straightforward. Many purposes now want vector search and metadata filtering however don’t wish to run a separate vector database service. Conventional server type methods are heavy for desktop instruments, cellular apps, or command line utilities. An embedded engine that behaves like SQLite however for embeddings suits this hole.
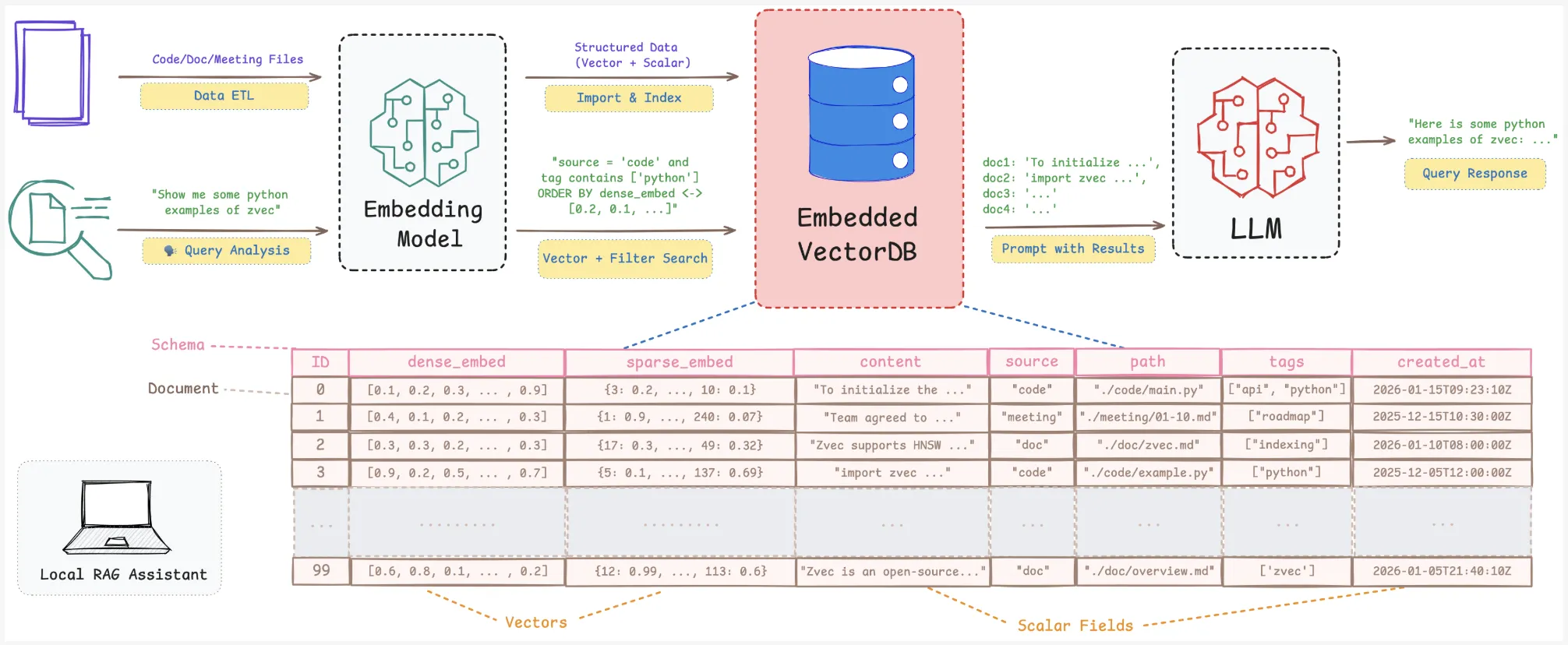
Why embedded vector search issues for RAG?
RAG and semantic search pipelines want greater than a naked index. They want vectors, scalar fields, full CRUD, and protected persistence. Native data bases change as information, notes, and mission states change.
Index libraries reminiscent of Faiss present approximate nearest neighbor search however don’t deal with scalar storage, crash restoration, or hybrid queries. You find yourself constructing your personal storage and consistency layer. Embedded extensions reminiscent of DuckDB-VSS add vector search to DuckDB however expose fewer index and quantization choices and weaker useful resource management for edge eventualities. Service primarily based methods reminiscent of Milvus or managed vector clouds require community calls and separate deployment, which is commonly overkill for on-device instruments.
Zvec claims to slot in particularly for these native eventualities. It offers you a vector-native engine with persistence, useful resource governance, and RAG oriented options, packaged as a light-weight library.
Core structure: in-process and vector-native
Zvec is carried out as an embedded library. You put in it with pip set up zvec and open collections immediately in your Python course of. There isn’t a exterior server or RPC layer. You outline schemas, insert paperwork, and run queries via the Python API.
The engine is constructed on Proxima, Alibaba Group’s excessive efficiency, manufacturing grade, battle examined vector search engine. Zvec wraps Proxima with an easier API and embedded runtime. The mission is launched beneath the Apache 2.0 license.
Present help covers Python 3.10 to three.12 on Linux x86_64, Linux ARM64, and macOS ARM64.
The design targets are express:
- Embedded execution in course of
- Vector native indexing and storage
- Manufacturing prepared persistence and crash security
This makes it appropriate for edge gadgets, desktop purposes, and zero-ops deployments.
Developer workflow: from set up to semantic search
The quickstart documentation reveals a brief path from set up to question.
- Set up the bundle:
pip set up zvec - Outline a
CollectionSchemawith a number of vector fields and elective scalar fields. - Name
create_and_opento create or open the gathering on disk. - Insert
Docobjects that include an ID, vectors, and scalar attributes. - Construct an index and run a
VectorQueryto retrieve nearest neighbors.
Instance:
import zvec
# Outline assortment schema
schema = zvec.CollectionSchema(
title="instance",
vectors=zvec.VectorSchema("embedding", zvec.DataType.VECTOR_FP32, 4),
)
# Create assortment
assortment = zvec.create_and_open(path="./zvec_example", schema=schema,)
# Insert paperwork
assortment.insert([
zvec.Doc(id="doc_1", vectors={"embedding": [0.1, 0.2, 0.3, 0.4]}),
zvec.Doc(id="doc_2", vectors={"embedding": [0.2, 0.3, 0.4, 0.1]}),
])
# Search by vector similarity
outcomes = assortment.question(
zvec.VectorQuery("embedding", vector=[0.4, 0.3, 0.3, 0.1]),
topk=10
)
# Outcomes: checklist of {'id': str, 'rating': float, ...}, sorted by relevance
print(outcomes)Outcomes come again as dictionaries that embody IDs and similarity scores. This is sufficient to construct a neighborhood semantic search or RAG retrieval layer on prime of any embedding mannequin.
Efficiency: VectorDBBench and eight,000+ QPS
Zvec is optimized for prime throughput and low latency on CPUs. It makes use of multithreading, cache pleasant reminiscence layouts, SIMD directions, and CPU prefetching.
In VectorDBBench on the Cohere 10M dataset, with comparable {hardware} and matched recall, Zvec studies greater than 8,000 QPS. That is greater than 2× the earlier leaderboard #1, ZillizCloud, whereas additionally considerably lowering index construct time in the identical setup.

These metrics present that an embedded library can attain cloud degree efficiency for prime quantity similarity search, so long as the workload resembles the benchmark situations.
RAG capabilities: CRUD, hybrid search, fusion, reranking
The function set is tuned for RAG and agentic retrieval.
Zvec helps:
- Full CRUD on paperwork so the native data base can change over time.
- Schema evolution to regulate index methods and fields.
- Multi vector retrieval for queries that mix a number of embedding channels.
- A in-built reranker that helps weighted fusion and Reciprocal Rank Fusion.
- Scalar vector hybrid search that pushes scalar filters into the index execution path, with elective inverted indexes for scalar attributes.
This lets you construct on gadget assistants that blend semantic retrieval, filters reminiscent of person, time, or kind, and a number of embedding fashions, all inside one embedded engine.
Key Takeaways
- Zvec is an embedded, in-process vector database positioned because the ‘SQLite of vector database’ for on-device and edge RAG workloads.
- It’s constructed on Proxima, Alibaba’s excessive efficiency, manufacturing grade, battle examined vector search engine, and is launched beneath Apache 2.0 with Python help on Linux x86_64, Linux ARM64, and macOS ARM64.
- Zvec delivers >8,000 QPS on VectorDBBench with the Cohere 10M dataset, attaining greater than 2× the earlier leaderboard #1 (ZillizCloud) whereas additionally lowering index construct time.
- The engine offers express useful resource governance by way of 64 MB streaming writes, elective mmap mode, experimental
memory_limit_mb, and configurableconcurrency,optimize_threads, andquery_threadsfor CPU management. - Zvec is RAG prepared with full CRUD, schema evolution, multi vector retrieval, in-built reranking (weighted fusion and RRF), and scalar vector hybrid search with elective inverted indexes, plus an ecosystem roadmap focusing on LangChain, LlamaIndex, DuckDB, PostgreSQL, and actual gadget deployments.
Take a look at the Technical details and Repo. Additionally, be happy to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
