
Query:
Think about your organization’s LLM API prices immediately doubled final month. A deeper evaluation exhibits that whereas person inputs look completely different at a textual content degree, a lot of them are semantically comparable. As an engineer, how would you determine and scale back this redundancy with out impacting response high quality?
What’s Immediate Caching?
Immediate caching is an optimization method utilized in AI programs to enhance velocity and scale back value. As a substitute of sending the identical lengthy directions, paperwork, or examples to the mannequin repeatedly, the system reuses beforehand processed immediate content material reminiscent of static directions, immediate prefixes, or shared context. This helps save each enter and output tokens whereas retaining responses constant.
Take into account a journey planning assistant the place customers often ask questions like “Create a 5-day itinerary for Paris targeted on museums and meals.” Even when completely different customers phrase it barely in another way, the core intent and construction of the request stays the identical. With none optimization, the mannequin has to learn and course of the complete immediate each time, repeating the identical computation and rising each latency and price.
With immediate caching, as soon as the assistant processes this request the primary time, the repeated components of the immediate—such because the itinerary construction, constraints, and customary directions—are saved. When the same request is shipped once more, the system reuses the beforehand processed content material as a substitute of ranging from scratch. This leads to sooner responses and decrease API prices, whereas nonetheless delivering correct and constant outputs.

What Will get Cached and The place It’s Saved
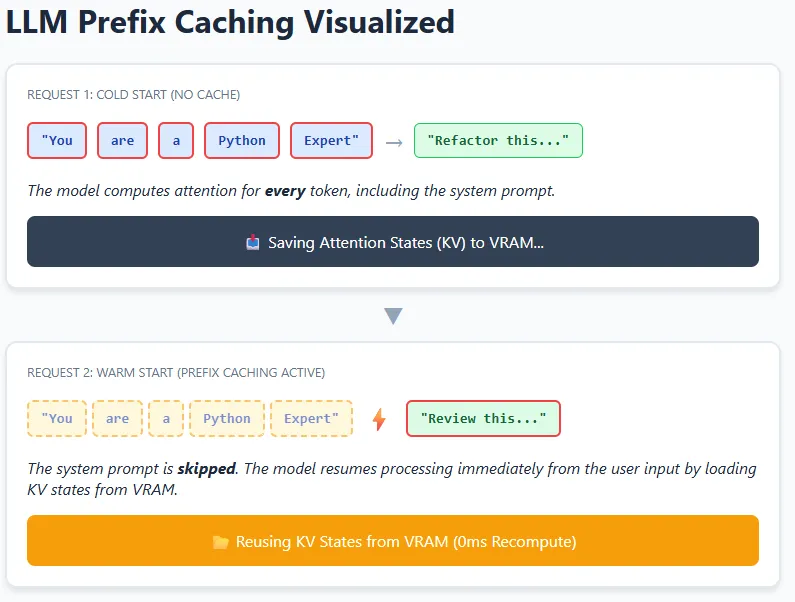
At a excessive degree, caching in LLM programs can occur at completely different layers—starting from easy token-level reuse to extra superior reuse of inside mannequin states. In follow, trendy LLMs primarily depend on Key–Worth (KV) caching, the place the mannequin shops intermediate consideration states in GPU reminiscence (VRAM) so it doesn’t should recompute them once more.
Consider a coding assistant with a hard and fast system instruction like “You’re an knowledgeable Python code reviewer.” This instruction seems in each request. When the mannequin processes it as soon as, the eye relationships (keys and values) between its tokens are saved. For future requests, the mannequin can reuse these saved KV states and solely compute consideration for the brand new person enter, such because the precise code snippet.
This concept is prolonged throughout requests utilizing prefix caching. If a number of prompts begin with the very same prefix—identical textual content, formatting, and spacing—the mannequin can skip recomputing that total prefix and resume from the cached level. That is particularly efficient in chatbots, brokers, and RAG pipelines the place system prompts and lengthy directions hardly ever change. The result’s decrease latency and diminished compute value, whereas nonetheless permitting the mannequin to totally perceive and reply to new context.

Structuring Prompts for Excessive Cache Effectivity
- Place system directions, roles, and shared context firstly of the immediate, and transfer user-specific or altering content material to the top.
- Keep away from including dynamic components like timestamps, request IDs, or random formatting within the prefix, as even small modifications scale back reuse.
- Guarantee structured knowledge (for instance, JSON context) is serialized in a constant order and format to forestall pointless cache misses.
- Usually monitor cache hit charges and group comparable requests collectively to maximise effectivity at scale.
Conclusion
On this scenario, the purpose is to scale back repeated computation whereas preserving response high quality. An efficient method is to investigate incoming requests to determine shared construction, intent, or frequent prefixes, after which restructure prompts in order that reusable context stays constant throughout calls. This permits the system to keep away from reprocessing the identical data repeatedly, resulting in decrease latency and diminished API prices with out altering the ultimate output.
For purposes with lengthy and repetitive prompts, prefix-based reuse can ship vital financial savings, nevertheless it additionally introduces sensible constraints—KV caches eat GPU reminiscence, which is finite. As utilization scales, cache eviction methods or reminiscence tiering grow to be important to stability efficiency positive aspects with useful resource limits.

I’m a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I’ve a eager curiosity in Knowledge Science, particularly Neural Networks and their utility in numerous areas.