
Tencent Hunyuan researchers have launched HY-MT1.5, a multilingual machine translation household that targets each cell gadgets and cloud methods with the identical coaching recipe and metrics. HY-MT1.5 consists of two translation fashions, HY-MT1.5-1.8B and HY-MT1.5-7B, helps mutual translation throughout 33 languages with 5 ethnic and dialect variations, and is accessible on GitHub and Hugging Face underneath open weights.
Mannequin household and deployment targets
HY-MT1.5-7B is an upgraded model of the WMT25 championship system Hunyuan-MT-7B. It’s optimized for explanatory translation and blended language eventualities, and provides native assist for terminology intervention, contextual translation and formatted translation.
HY-MT1.5-1.8B is the compact variant. It has lower than one third the parameters of HY-MT1.5-7B however delivers comparable translation efficiency within the reported benchmarks. After quantization, the 1.8B mannequin can run on edge gadgets and assist actual time translation.
The quantized HY-MT1.5-1.8B operates on gadgets with about 1 GB of reminiscence and reaches a median response time of about 0.18 seconds for Chinese language inputs of round 50 tokens, whereas surpassing mainstream business translation APIs in high quality. HY-MT1.5-7B targets server and excessive finish edge deployment, the place latency round 0.45 seconds is appropriate in trade for greater high quality.
Holistic coaching framework
The analysis workforce defines HY-MT1.5 as a translation particular language mannequin educated with a multi stage pipeline.
The pipeline has 5 essential parts:
- Basic pre coaching: The bottom mannequin is first pre-trained on giant scale multilingual textual content with a language modeling goal. This builds shared representations throughout languages.
- MT oriented pre coaching: The mannequin is then uncovered to parallel corpora and translation oriented goals. This step aligns the technology distribution with actual translation duties relatively than open ended textual content technology.
- Supervised high quality tuning: Prime quality sentence and doc stage parallel knowledge is used to high quality tune the mannequin with supervised loss. This stage sharpens literal correctness, area protection and path particular conduct, resembling ZH to EN versus EN to ZH.
- On coverage distillation from 7B to 1.8B: HY-MT1.5-7B is used as a trainer for HY-MT1.5-1.8B. The analysis workforce collects about 1 million monolingual prompts throughout the 33 languages, runs them by the trainer and makes use of reverse Kullback Leibler divergence on the coed rollouts to match the trainer distribution. This yields a 1.8B pupil that inherits a lot of the 7B mannequin’s translation conduct with a lot decrease value.
- Reinforcement studying with rubrics based mostly analysis: Within the remaining stage, each fashions are optimized with a gaggle relative coverage optimization model algorithm and a rubrics based mostly reward mannequin. Human reviewers rating translations on a number of axes resembling accuracy, fluency, idiomaticity and cultural appropriateness. The reward mannequin distills these scores and guides the coverage replace.
This pipeline is restricted to machine translation. It differs from chat oriented LLM coaching by combining translation centric supervised knowledge, on coverage distillation throughout the translation area and RL tuned with high quality grained translation rubrics.
Benchmark outcomes towards open and business methods
HY-MT1.5 is evaluated on Flores 200, WMT25 and a Mandarin to minority language benchmark utilizing XCOMET-XXL and CometKiwi.
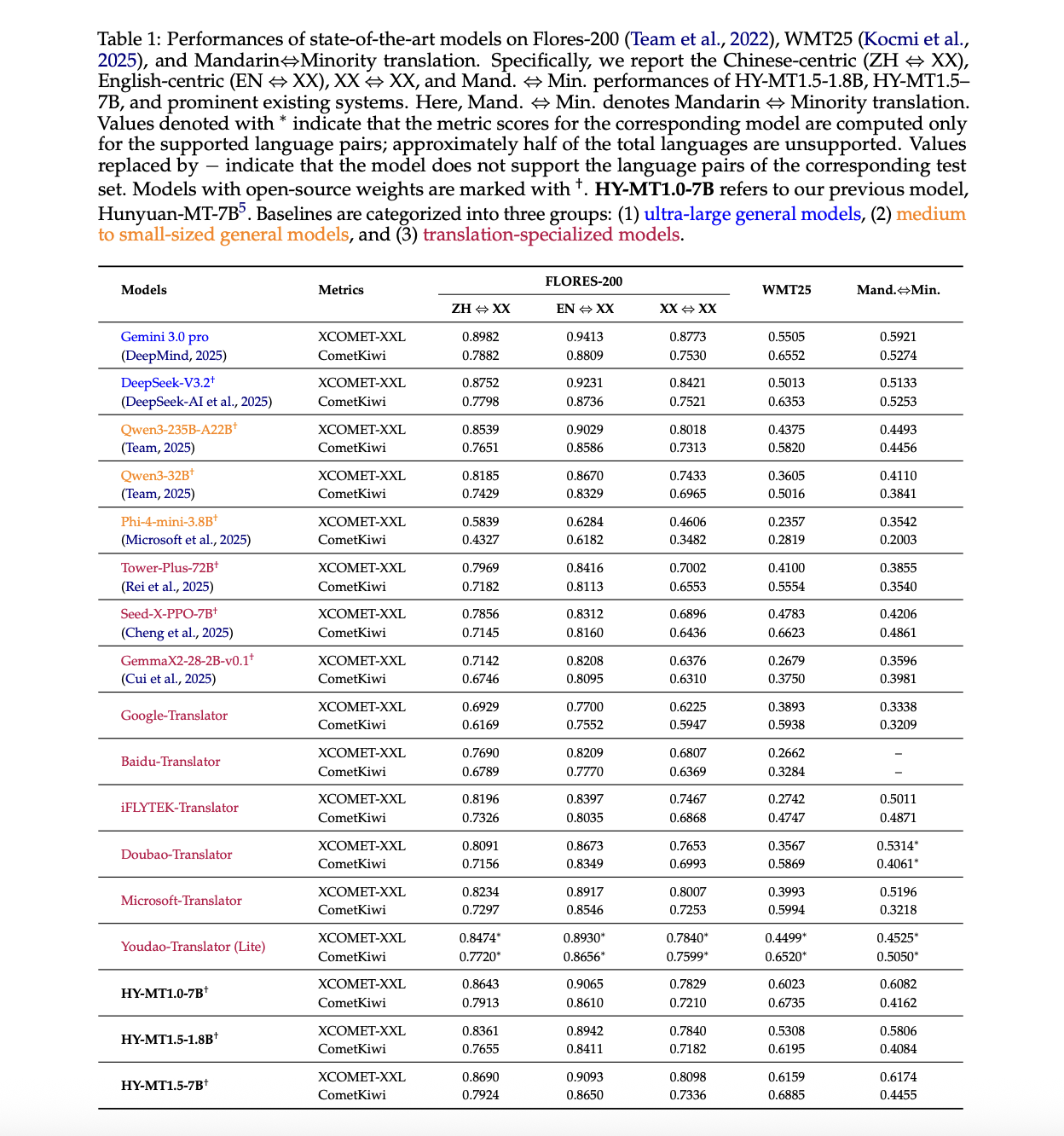
Key outcomes from the above Desk within the report:
- On Flores 200, HY-MT1.5-7B reaches XCOMET-XXL scores of 0.8690 for ZH to XX, 0.9093 for EN to XX and 0.8098 for XX to XX. It outperforms translation specialised fashions resembling iFLYTEK Translator and Doubao Translator and matches or exceeds medium sized normal fashions like Qwen3-235B-A22B.
- On WMT25, HY-MT1.5-7B reaches XCOMET-XXL 0.6159. That is about 0.065 greater than Gemini 3.0 Professional and considerably above translation oriented fashions resembling Seed-X-PPO-7B and Tower-Plus-72B. HY-MT1.5-1.8B scores 0.5308, which nonetheless exceeds many medium sized normal fashions and translation methods.
- On Mandarin to minority language pairs, HY-MT1.5-7B achieves 0.6174 in XCOMET-XXL, greater than all baselines together with Gemini 3.0 Professional. The 1.8B variant reaches 0.5806 and nonetheless surpasses a number of very giant fashions like DeepSeek-V3.2.
In human analysis on a 0 to 4 scale for Chinese language to English and English to Chinese language, HY-MT1.5-1.8B achieves a median rating of two.74, which is greater than Baidu, iFLYTEK, Doubao, Microsoft and Google translator methods underneath the identical protocol.
Sensible options for product use
The fashions expose three immediate pushed capabilities that matter in manufacturing methods:
- Terminology intervention: A immediate template allows you to inject time period mappings resembling “混元珠 → Chaos Pearl”. With out the mapping, the mannequin outputs an ambiguous transliteration. With the mapping, it enforces a constant area particular time period. That is essential for authorized, medical or model constrained content material.
- Context conscious translation: A second template accepts a context block plus the sentence to translate. The report reveals the phrase “pilot” misinterpreted as an individual when context is absent. When a paragraph about TV collection is added, the mannequin appropriately interprets “pilot” as an episode.
- Format preserving translation: A 3rd template wraps the supply in
These are carried out as immediate codecs, so they’re out there even once you name the general public weights by commonplace LLM stacks.
Quantization and edge deployment
HY-MT1.5-1.8B is evaluated with FP8 and Int4 put up coaching quantization utilizing GPTQ.
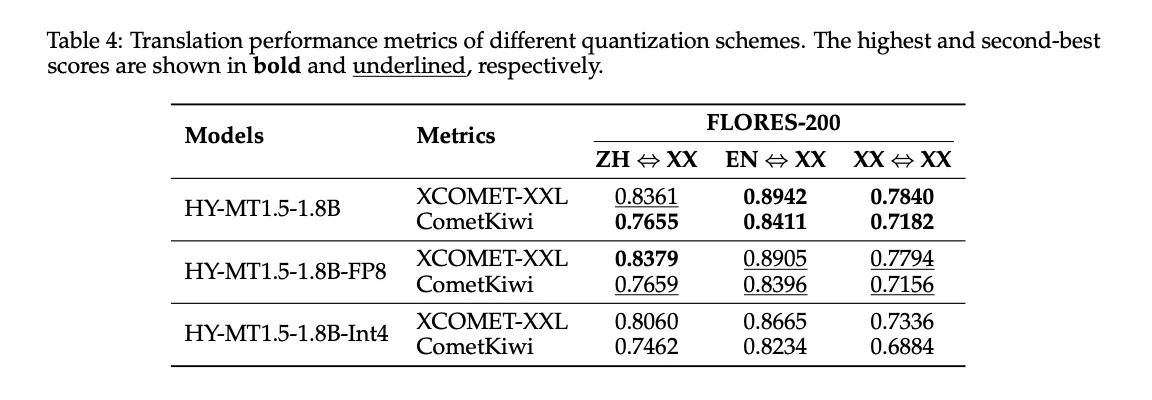
The above Desk 4 reveals:
- FP8 retains XCOMET-XXL scores very near the total precision mannequin, for instance 0.8379 versus 0.8361 for ZH to XX.
- Int4 reduces measurement additional however introduces clear high quality drops on Flores 200.
On Hugging Face, Tencent publishes each FP8 and GPTQ Int4 variants for HY-MT1.5-1.8B and HY-MT1.5-7B, together with GGUF variations for native inference stacks. Quantization is the mechanism that permits the reported 1 GB reminiscence deployment and low latency on client {hardware}.
Key Takeaways
- HY-MT1.5 is a 2 mannequin translation household, HY-MT1.5-1.8B and HY-MT1.5-7B, supporting mutual translation throughout 33 languages plus 5 dialect or variant kinds, launched with open weights on GitHub and Hugging Face.
- HY-MT1.5-1.8B is a distillation based mostly edge mannequin that runs on about 1 GB reminiscence with round 0.18 seconds latency for 50 token Chinese language inputs, whereas reaching trade main efficiency amongst fashions of comparable measurement and surpassing most business translation APIs.
- HY-MT1.5-7B is an upgraded WMT25 champion system that reaches roughly 95 p.c of Gemini 3.0 Professional on Flores 200 and surpasses it on WMT25 and Mandarin minority benchmarks, competing with a lot bigger open and closed fashions.
- Each fashions are educated with a holistic translation particular pipeline that mixes normal and MT oriented pre coaching, supervised high quality tuning, on coverage distillation and reinforcement studying guided by rubric based mostly human analysis, which is essential to their high quality and effectivity commerce off.
- HY-MT1.5 exposes manufacturing oriented options by prompts, together with terminology intervention, context conscious translation and format preserving translation, and ships FP8, Int4 and GGUF variants so groups can deploy on gadgets or servers with commonplace LLM stacks.
Try the Paper, Model Weights on HF and GitHub Repo. Additionally, be happy to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.

Michal Sutter is an information science skilled with a Grasp of Science in Information Science from the College of Padova. With a stable basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at remodeling advanced datasets into actionable insights.