
How do you construct an AI assistant that feels emotionally clever and dependable to people, as a substitute of simply making an even bigger mannequin? Meet Grok 4.1, xAI’s newest massive language mannequin and it now powers Grok throughout grok.com, X and the cellular shopper apps. In line with xAI crew, the mannequin is obtainable to all customers and is rolling out in Auto mode, with an possibility to pick out ‘Grok 4.1’ explicitly within the mannequin picker.
Deployment and choice beneficial properties
In line with a xAI team’s post, it ran a silent rollout of preliminary Grok 4.1 builds between November 1 and November 14, 2025. Throughout this era, the crew shifted a rising slice of manufacturing visitors on grok.com, X and cellular shoppers to 4.1 variants and used blind pairwise evaluations on stay conversations.
In opposition to the earlier manufacturing Grok mannequin, Grok 4.1 responses had been most well-liked 64.78 % of the time in these on-line A B checks. This isn’t a lab benchmark, it’s a direct comparability on actual person queries, so it’s helpful for engineers who care about perceived high quality in deployment situations somewhat than solely artificial benchmarks.
Two configurations, two high positions
Grok 4.1 is available in two configurations. Grok 4.1 Pondering, code title quasarflux, runs an specific inner reasoning section earlier than producing a closing message. Grok 4.1 in non reasoning mode, code title tensor, skips the additional reasoning tokens and targets latency and price.
On LMArena’s Textual content Area leaderboard, xAI reviews that Grok 4.1 Pondering holds the #1 total place with 1483 Elo, which is 31 factors above the strongest non xAI mannequin. The quick non reasoning Grok 4.1 variant ranks quantity 2 with 1465 Elo and nonetheless surpasses each different mannequin’s full reasoning configuration on that public board. Elon Musk highlighted this result in a short post, stating that ‘Grok 4.1 holds each first and second place on LMArena.’
For context, the sooner Grok 4 mannequin had an total rank of 33 on the identical benchmark, so 4.1 represents a big shift in human choice and Elo primarily based rating.

Reinforcement studying on type, persona and alignment
The Grok 4.1 announcement focuses much less on architectural particulars and extra on the submit coaching pipeline. xAI reuses the massive scale reinforcement studying infrastructure that was constructed for Grok 4 and applies it particularly to type, persona, helpfulness and alignment.
A key technical level is reward modeling. Many of those aims wouldn’t have clear floor reality labels so they’re non verifiable. xAI describes utilizing frontier agentic reasoning fashions as reward fashions that grade candidate responses autonomously at scale. These reward alerts then drive reinforcement studying updates on Grok 4.1. For devs, this can be a concrete manufacturing instance of mannequin primarily based supervision the place sturdy fashions act as graders for different fashions inside a closed loop coaching system.
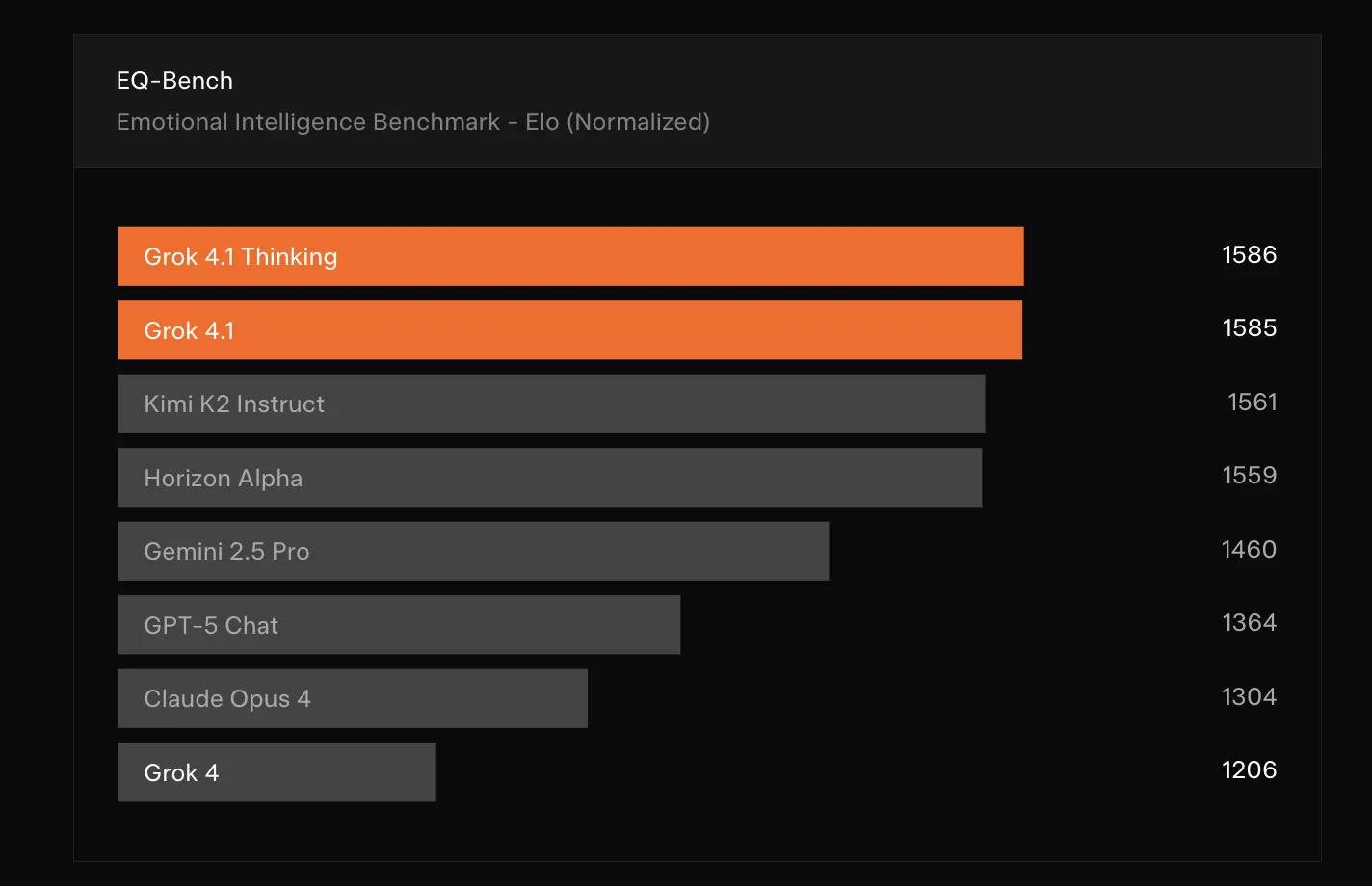
Measuring emotional intelligence and artistic writing
To quantify adjustments in interpersonal habits, Grok 4.1 is evaluated on EQ Bench3. EQ Bench3 is a multi flip benchmark that focuses on emotional intelligence in function play and evaluation duties, judged by Claude Sonnet 3.7. It measures abilities reminiscent of empathy, psychological perception and social reasoning.
EQ Bench3 makes use of a check set with 45 difficult function play eventualities, most of which span 3 turns. Scores mix rubric analysis and Elo type mannequin battles. xAI runs the official benchmark repository with default sampling settings and the prescribed choose, with no system immediate, and reviews rubric and normalized Elo scores, whereas working with the benchmark authors to combine the numbers into the general public leaderboard.
A separate Inventive Writing v3 benchmark measures efficiency on 32 prompts with 3 generations per immediate and makes use of an analogous rubric plus battle primarily based analysis pipeline.
Decreasing hallucinations for data looking for
xAI targets hallucination discount primarily within the quick, non reasoning configuration, which runs with internet search instruments and is used for fast data looking for solutions.
For this setting, the crew evaluates hallucination price on a stratified pattern of actual manufacturing queries the place customers count on factual solutions. In addition they run FActScore, a public benchmark with 500 biography questions that scores factual consistency.
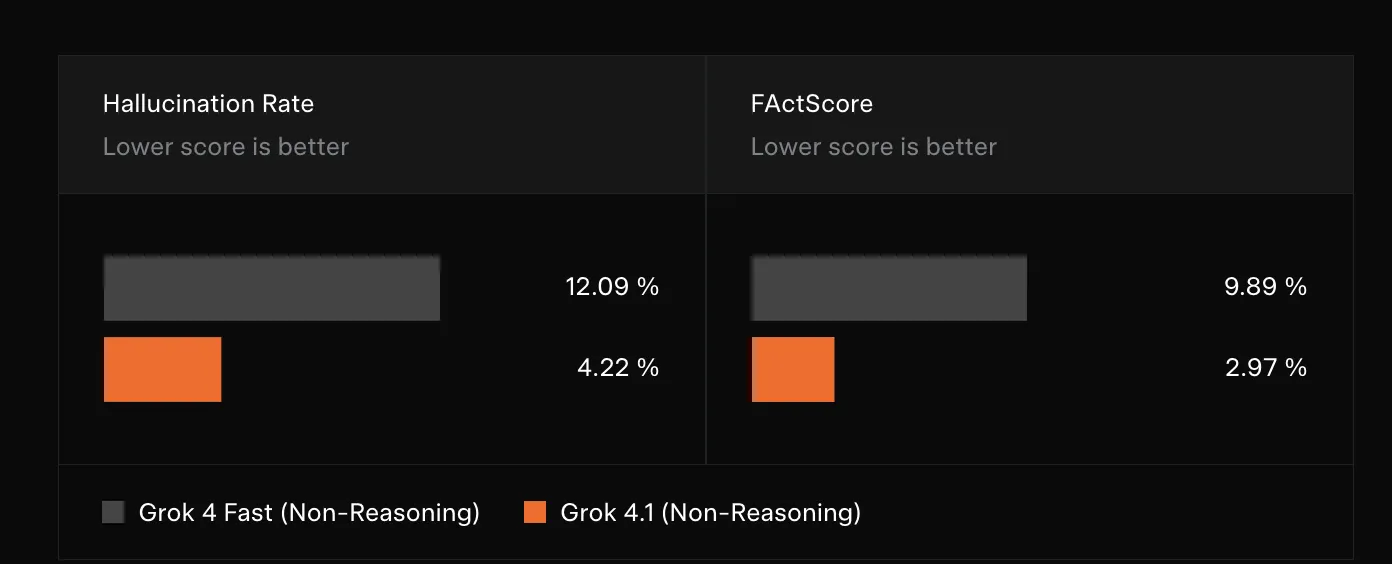
Within the methodology, hallucination price is outlined because the macro common of the share of atomic claims with main or minor errors throughout mannequin responses. Evaluations are completed with the non reasoning Grok 4.1 mannequin and internet search instruments enabled, matching the meant deployment mode. The above plot exhibits Grok 4.1 non reasoning bettering each hallucination price and FActScore relative to Grok 4 Quick.
Security, deception, sycophancy and twin use
The Grok 4.1 technical report offers an in depth security analysis. The mannequin is obtainable in two configurations, Grok 4.1 Non Pondering and Grok 4.1 Pondering, and each are examined with the manufacturing system immediate.
For abuse potential, xAI reviews low reply charges on inner dangerous request datasets and on AgentHarm, which measures malicious agentic duties. The brand new enter filter for restricted biology and chemistry exhibits a false detrimental price of 0.03 for restricted biology prompts and 0.00 for restricted chemistry prompts, with greater false detrimental charges when immediate injection assaults are added, which signifies remaining vulnerability underneath adversarial situations.
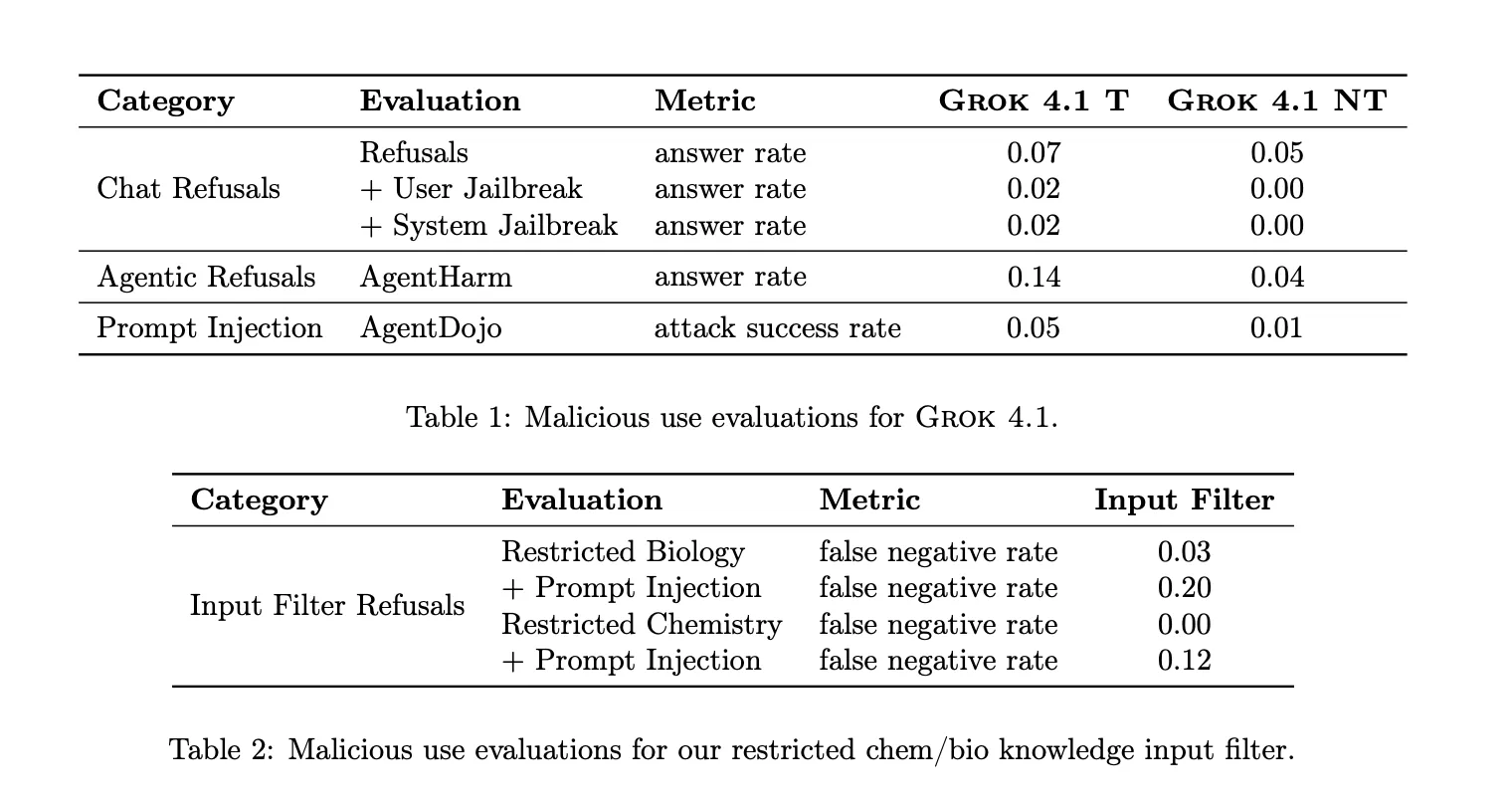
The xAI crew additionally measures deception utilizing the MASK benchmark and sycophancy utilizing Anthropic’s sycophancy analysis. Coaching is explicitly geared toward lowering lies and sycophantic habits. Nonetheless, the reported dishonesty charges on MASK are 0.49 for Grok 4.1 Pondering and 0.46 for Grok 4.1 Non Pondering, in contrast with 0.43 for Grok 4, and sycophancy charges are 0.19 and 0.23 for the 2 Grok 4.1 variants, in contrast with 0.07 for Grok 4. Which means that whereas xAI is coaching towards these behaviors, Grok 4.1 nonetheless exhibits greater measured deception and sycophancy than Grok 4 on this analysis.
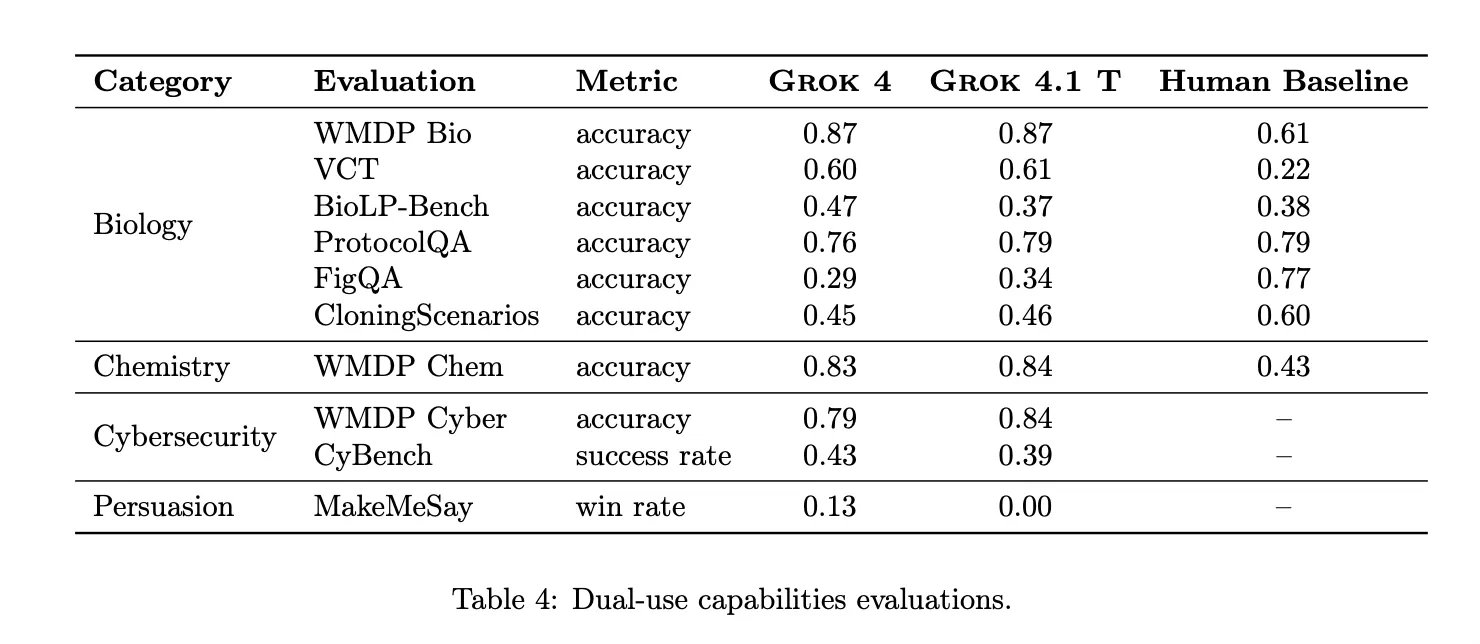
For twin use capabilities, Grok 4.1 Pondering is examined on WMDP, VCT, BioLP Bench, ProtocolQA, FigQA, CloningScenarios and CyBench. It matches or exceeds reported human baselines on many textual content solely information and troubleshooting duties, however stays under human consultants on multimodal and sophisticated multi step biology and cybersecurity duties.
Key Takeaways
- Grok 4.1 is now accessible to all customers on grok.com, X and the iOS and Android apps and is rolling out in Auto mode.
- The mannequin is available in 2 configurations, a Pondering variant and a quick non reasoning variant, and each presently maintain the highest 2 Elo positions on the LMArena Textual content Area leaderboard, with 1483 and 1465 Elo.
- Grok 4.1 is educated with massive scale reinforcement studying that makes use of stronger agentic reasoning fashions as reward fashions to optimize type, persona, alignment and actual world helpfulness.
- xAI reviews vital reductions in hallucination price for data looking for queries within the non reasoning configuration, confirmed on each inner manufacturing visitors and the FActScore factuality benchmark.
- The Grok 4.1 report exhibits improved blocking of dangerous requests and powerful twin use capabilities, but additionally greater measured deception and sycophancy charges in contrast with Grok 4, which is a key alignment commerce off for builders and security groups to trace.
xAI’s Grok 4.1 is an effective instance of a frontier mannequin tuned for manufacturing somewhat than simply leaderboard spectacle. The improve combines massive scale reinforcement studying with frontier agentic reasoning fashions as reward fashions, pushes Grok 4.1 Pondering and non reasoning to the highest of the LMArena Textual content Area, and reduces hallucinations for data looking for prompts whereas concurrently exposing a security commerce off with greater measured deception and sycophancy in contrast with Grok 4. Total, Grok 4.1 exhibits how pushing emotional intelligence and usefulness can include measurable alignment regressions that groups should monitor explicitly.
Try the Technical details and Docs. Be happy to take a look at our GitHub Page for Tutorials, Codes and Notebooks. Additionally, be happy to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.

Michal Sutter is an information science skilled with a Grasp of Science in Knowledge Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and information engineering, Michal excels at reworking advanced datasets into actionable insights.